Warszawa 2019, (wersja poprawiona 2023, 2025)
Niniejsza instrukcja stanowi możliwie zwięzłe przedstawienie założeń projektu w zakresie edycji nutowych. Z uwagi na przyjęte cele, głównym formatem zapisu informacji muzycznej jest symboliczny, tekstowy format Humdrum. Pliki zapisane w tym formacie zwykle otrzymują rozszerzenie krn, zatem w dalszej części instrukcji będą oznaczane skrótowo: krn. Pliki uzyskane w procesie wykonywania transkrypcji (tworzone w programach MuseScore, Finale, Sibelius i in.) powinny być zapisywane do ujednoliconego formatu MusicXML – w dalszej części instrukcji oznaczane w skrócie: xml.
Transkrypcja dyplomatyczna – transkrypcja zapisu źródłowego za pomocą współczesnej notacji muzycznej do wersji możliwie wiernie oddającej oryginał. W transkrypcji tego typu powtarza się dosłownie zapis źródłowy, odtwarzając także błędy i braki, cechujące źródło.
Edycja krytyczna – edycja, w której poprawiono ewidentne (a także mniej oczywiste) błędy w źródle, uzupełniono braki, uwspółcześniono i ujednolicono zapis zgodnie z zasadami współczesnej ortografii muzycznej. Edycja krytyczna uzupełniona jest o komentarz rewizyjny, w którym odnotowane precyzyjnie wszelkie zmiany w stosunku do zapisu źródłowego.
Plik xml – bardziej precyzyjnie plik MusicXML, czyli zapis informacji muzycznej w formacie pliku o strukturze drzewa. W zasadzie jest to język (eXternsible Markup Language) zaprojektowany do organizacji i przechowywania danych. Plik xml jest plikiem tekstowym i może być otwarty i edytowany w każdym edytorze tekstowym. Jest to główny format wymiany danych pomiędzy programami służącymi do edycji nut.
Plik krn – plik tekstowy zapisany zgodnie z zasadami składni Humdrum. Składnia Humdrum pozwala na precyzyjne i jednoznaczne zapisanie informacji muzycznej w sposób ustrukturyzowany. Jest to zapis symboliczny, tzn. za pomocą symboli tekstowych zapisywana jest treść muzyczna. Format Humdrum pozwala za pomocą narzędzi do renderowania (wyświetlania) nut tworzyć partytury cyfrowe. Jednocześnie zapis ten pozwala na łatwe przekształcanie i operowanie danymi, co umożliwia wykonywanie analizy skomputeryzowanej i tworzenie różnych narzędzi, jak np. wyszukiwarki muzyczne.
Konwersja – zmiana jednego formatu zapisu na inny. W programach komercyjnych (Finale, Sibelius) wbudowano konwertery, pozwalające na eksport szyfrowanego pliku w formacie natywnym do otwartego formatu xml. Dla formatów otwartych (xml, krn) istnieją konwertery pozwalające bezpośrednio i łatwo zmieniać (także masowo) format zapisu.
Lekcja – (łac. lectio) odczytanie w transkrypcji tekstu oryginalnego. W przypadku zapisów niejasnych, wieloznacznych, poszczególne lekcje różnych redaktorów jednego źródła mogą się różnić.
Podstawowe cele, jakie przyjęto w projekcie w zakresie przygotowywanych transkrypcji, to:
przygotowanie najwyższej jakości składów,
stworzenie bazy repertuaru muzyki polskiej,
możliwie wierne zakodowanie informacji zapisanej w źródłach,
wytworzenie materiału, który będzie mógł być wykorzystany do analizy skomputeryzowanej i stworzenia wyszukiwarki muzycznej.
Realizacja tych założeń wymaga postępowania z należytą starannością w trakcie tworzenia transkrypcji oraz ich dalszego opracowania. W projekcie tworzone będą zasadniczo dwa typy transkrypcji:
tzw. transkrypcja dyplomatyczna (możliwie wiernie oddająca zapis źródłowy),
wydanie krytyczne (edycja uwzględniająca ingerencje i poprawki redaktora wraz z ich wykazem w formie komentarza rewizyjnego).
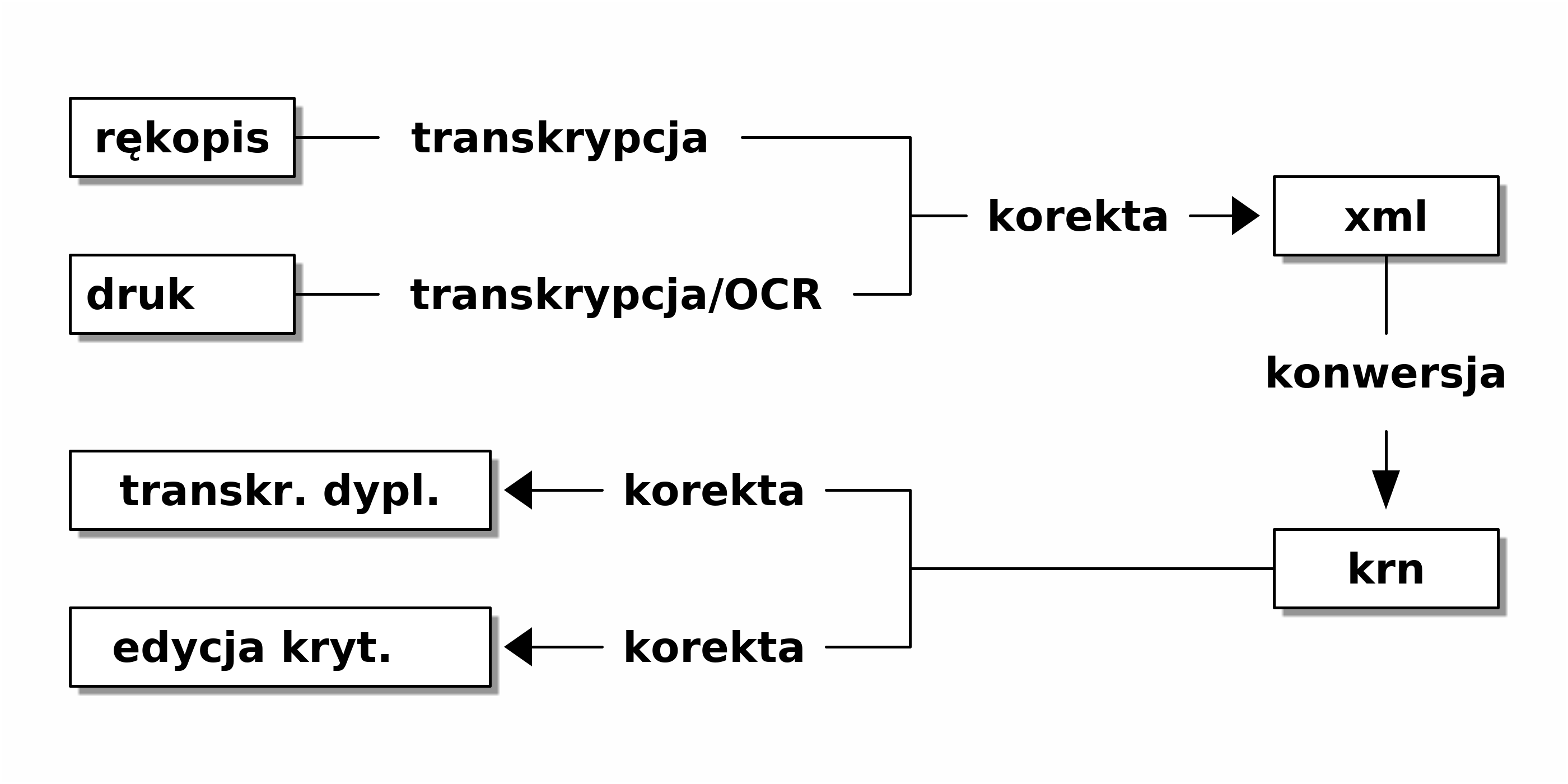
Najogólniej proces tworzenia edycji polega na (1) pozyskaniu danych poprzez ręczne wykonanie transkrypcji lub OCR1 (w przypadku nadających się do tego druków muzycznych), (2) zapisaniu danych do formatu xml, (3) konwersji do formatu krn, (4) korekty zapisu do wersji możliwie najbardziej zbliżonej do źródła, (5) stworzeniu edycji krytycznej (zob. przyk. 1.1).
Główne cele, dla których przyjęto wskazaną metodologię pracy, to zagwarantowanie maksymalnie efektywnego przepływu pracy i danych a także zapewnienie możliwie maksymalnej kontroli jakości danych. Dzięki założonej metodzie każda transkrypcja dyplomatyczna jest poddana co najmniej dwukrotnej rewizji przez dwie różne osoby, zaś edycja krytyczna dwukrotnej lub trzykrotnej rewizji przez różne osoby. Ma to zagwarantować najwyższą jakość danych nie tylko z uwagi na konieczność spełnienia wysokich standardów edycji krytycznych, ale także zapewnić, że dane poddawane późniejszej analizie (także analizie statystycznej obejmującej całe korpusy dzieł) nie zawierają błędów mogących zniekształcać wyniki badań.
Z powyższych założeń uwidocznionych na diagramie wynika metodologia pracy oraz specyficzne zasady edycji stosowane przez redaktorów. Podział prac a także konieczność posiadania odrębnych kompetencji wymaga dokonania podziału redaktorów na dwie grupy:
redaktorzy plików xml,
redaktorzy plików krn.
Redaktorzy plików xml powinni zapoznać się przede wszystkim z zagadnieniami w rozdziale 3.1. Do redaktorów plików krn skierowany jest szczególnie rozdział 3.2 oraz rozdział 5. Niezależnie od fragmentów instrukcji zawierających szczegółowe wskazówki dla poszczególnych grup redaktorów, każdy z nich zobowiązany jest zapoznać się z całym dokumentem. Zrozumienie procesu oraz tego, jak powinny zostać przygotowane dane, jest kluczowe dla właściwej realizacji prac.
Na gruncie klasycznego edytorstwa muzycznego wskazuje się kilka typów edycji, w tym m.in. edycję krytyczną, wydanie urtekstowe, edycję wykonawczą (praktyczną), transkrypcję dyplomatyczną, wydanie faksymilowe i in. W niniejszej instrukcji interesują nas dwa spośród powyższych typów, czyli transkrypcja dyplomatyczna oraz wydanie krytyczne.
Wydania krytyczne muszą spełniać wysokie standardy pracy naukowej, zostać opatrzone stosownym wstępem (z możliwie pełnym opisem źródła, biogramu kompozytora) oraz – obowiązkowo – tzw. komentarzem rewizyjnym. Komentarz ten stanowi opis zmian w stosunku do źródła wprowadzonych w edycji przez redaktora. Zmiany takie niemal we wszystkich rodzajach dawniejszych źródeł są niezbędne. Mogą one dotyczyć np. pewnych niezrozumiałych już obecnie konwencji notacyjnych, stanowią niejednokrotnie uzupełnienia zapisów niekonsekwentnych (jak np. częste w rękopisach pomijanie kreski taktowej bądź akcydencji (znaków chromatycznych). W tym sensie praca redaktora stanowi ,,krytykę” źródła. Komentarz rewizyjny stanowiąc listę wszelkich odstępstw od oryginału powinien pozwolić w całości zrekonstruować oryginalną jego treść. Ma to na celu umożliwienie badaczom oraz muzykom podjęcie ewentualnie innych niż proponowane przez redaktora decyzji dotyczących wątpliwych momentów zapisu muzycznego. Warto w tym momencie przypomnieć, że w edytorstwie muzycznym a także — szerzej — wszelkiej krytyce tekstu (także literackiego) jedną z głównych zasad jest zasada difficilior lectio potior (dosł. ,,trudniejsza lekcja ma większą moc”). Zasada ta oznacza, że w przypadku sprzecznych przekazów, mniej oczywiste, wydające się w pierwszej chwili błędne odczytanie tekstu, należy uznać za bliższe oryginalnemu zamysłowi autora. Zasada ta wynika z przyjęcia tezy, że skryptorzy, kopiści mają tendencję do automatycznego poprawiania np. nietypowej pisowni, w efekcie czego powstają ujednolicenia, które nie były zamysłem twórcy tekstu i w istocie stanowią zagubienie czynnika ,,oryginalności” oraz bliskości pierwowzoru. Na gruncie realizowanego projektu wszelkie zasady (omówione bardziej szczegółowo w rozdziale 5) pozostają w mocy, natomiast zupełnie inaczej przebiegać będzie proces tworzenia samego komentarza rewizyjnego. Wypisanie różnic pomiędzy źródłem a jego edycją niejednokrotnie stanowi najbardziej czasochłonną część procesu edycyjnego. W projekcie NIFC z założenia będzie to proces automatyczny i wykonywany przez odpowiednie narzędzia programistyczne.
W dobie coraz powszechniejszych i łatwo dostępnych baz i repozytoriów cyfrowych, dzięki którym można zapoznać się z oryginałem, tworzenie transkrypcji dyplomatycznych wydaje się coraz mniej celowe, jak wskazuje m.in. John Caldwell.2 W projekcie NIFC jest to niemal oczywiste, ponieważ transkrypcje będą tworzone wyłącznie na bazie źródeł bądź zdigitalizowanych przez NIFC, bądź dostępnych w domenie publicznej. Jednak z uwagi na metodologię pracy oraz sposób działania narzędzi komputerowych tworzenie takich transkrypcji jest konieczne. Stanowią one ogniwo pośrednie pomiędzy źródłem a jego krytyczną edycją. Jak wskazano pliki krn, czyli główny typ formatu, w jakim zapisywane są partytury w projekcie, jest plikiem tekstowym. Plik krn w dużym uproszczeniu przypomina arkusz kalkulacyjny, w którym w kolumnach wypisane są poszczególne głosy kompozycji3, zaś poszczególne linie to kolejne „wydarzenia” w utworze. Przyjmijmy, że mamy jedno taktowy, dwugłosowy utwór w metrum 4/4, w którym w każdym z głosów występują trzy ćwierćnuty i jedna pauza ćwierćnutowa. Plik krn będzie zatem posiadał dwie kolumny, zaś sam zapis nutowy będzie miał cztery linijki (nie licząc innych elementów, jak np. zapis kluczy, metrum, kresek taktowych etc.). Bardzo czytelną ilustrację tego zapisu stanowi zaczerpnięty ze strony dokumentacji Humdrum4 przykład, który prezentujemy poniżej (przyk. 2.1. Przdatne będą również tabele 2.1, 2.2 i 2.3, prezentujące kodowanie podstawowych zjawisk muzycznych – wartości rytmicznych, wysokości dźwięków i akcydencji.

| HUMDRUM | WARTOŚĆ RYTMICZNA |
|---|---|
1 |
cała nuta |
2 |
półnuta |
4 |
ćwierćnuta |
........ |
.............. |
32 |
trzydziestodwójka |
4. |
ćwierćnuta z kropką |
8.. |
ósemka z dwiema kropkami |
........ |
.............. |
| HUMDRUM | WYSOKOŚĆ DŹWIĘKU |
|---|---|
xxx |
oktawa trzykreślna, np. ccc =
c3 |
xx |
oktawa dwukreślna, np. aa =
a2 |
x |
oktawa razkreślna, np. g =
g1 |
X |
oktawa mała, np. G = g |
XX |
oktawa wielka, np. BB = H
(sic!) |
XXX |
oktawa kontra, np. FFF =
F1 |
........ |
.............. |
| HUMDRUM | ZNACZENIE |
|---|---|
## |
podwójny krzyżyk |
# |
krzyżyk |
n |
kasownik |
- |
bemol |
-- |
podwójny bemol |
Nie jest to miejsce aby szczegółowo omawiać sposób zapisu muzyki w formacie Humdrum. Jednak zrozumienie podstaw oraz samej idei pozwoli lepiej pojąć metody pracy w projekcie oraz — co szczególnie ważne — rolę redaktora.
Automatyzacja procesu tworzenia komentarza rewizyjnego polega na
wykonaniu komputerowego porównania dwu plików tekstowych: (1)
transkrypcji dyplomatycznej i (2) edycji krytycznej. Narzędzia
komputerowe bardzo dobrze radzą sobie z tego typu zadaniami. Na
najprostszym przykładzie wygląda to tak. Załóżmy, że w źródle mamy
zapisaną ćwierćnutę c1. Redaktor wie jednak, że w tym miejscu
powinien znajdować się krzyżyk podwyższający c1 na
cis1. W pliku transkrypcji dyplomatycznej znajdzie się zatem
zapis: 4c zaś w pliku edycji krytycznej 4c#.
Narzędzia komputerowe porównają obydwa pliki i wskażą różnice pomiędzy
nimi:5
4c# – 4c = #
Analogicznie do powyższej sytuacji możemy wskazać na różnice w wysokości dźwięków, wartościach rytmicznych etc. Każda, najdrobniejsza nawet różnica pomiędzy plikami zostanie wskazana. Lista owych różnic stanowi istotę komentarza rewizyjnego. Oczywiście wskazane przykłady są niezwykle proste, jednak Humdrum to nie tylko rodzaj zapisu, ale także bardzo złożony system oraz zestaw kilkudziesięciu programów, za pomocą których można wykonywać bardzo skomplikowane operacje.
Istotą przedstawionych przykładów jest wskazanie, jak niezwykle ważne jest, aby transkrypcja dyplomatyczna możliwie najwierniej odzwierciedlała zapis źródłowy. W przeciwnym razie efekt porównania da fałszywe wyniki.
Tradycyjne metody pracy redaktora przygotowującego edycję krytyczną można sprowadzić do kilku najważniejszych etapów. W pierwszej kolejności tworzona jest transkrypcja – już na tym etapie niejednokrotnie wprowadzane są korekty oczywistych pomyłek oraz uzupełniane braki i pominięcia.6 Następnie wykonywana jest głębsza korekta – poprawiane są współbrzmienia, ujednolicane oznaczenia dynamiczne i artykulacyjne, dodawane brakujące akcydencje etc. Praca ta wymaga częstego sięgania do źródła, np. w tym celu aby porównać analogiczne do siebie fragmenty kompozycji i sprawdzić, czy to porównanie pomaga rozstrzygnąć wątpliwości. W efekcie powstaje edycja poprawiona i uzupełniona. Stopień ingerencji edytora zależny jest najczęściej od przyjętych założeń wydawniczych lub celu publikacji. W edycjach krytycznych przyjmuje się możliwie najmniejszą ilość ingerencji redaktora. Kolejnym etapem pracy jest ponowne porównanie tak sporządzonej edycji ze źródłem i wypisanie wszystkich ingerencji. W ten sposób powstaje komentarz rewizyjny. Ten etap pracy bywa najbardziej żmudny a jednocześnie jest niejednokrotnie źródłem pomyłek.
W projekcie NIFC dzięki zastosowaniu narzędzi wypracowanych przez twórcę Humdrum, Davida Hurona z Ohio State University7 i od wielu lat rozwijanych na Uniwersytecie Stanforda w Center for Computer Assisted Research in the Humanities8 m.in. przez Craiga Sappa współpracującego z NIFC, można ten proces uprościć. Co ważne, tworzenie komentarza rewizyjnego zostaje zautomatyzowane co redukuje do minimum ryzyko błędu i czyni sam proces nieporównanie szybszym. Umożliwia też redaktorowi skupienie się na wyłącznie merytorycznej pracy, czyli analizie źródła i podejmowaniu w oparciu o nią konkretnych decyzji.
Przy takiej metodologii pracy dochodzi do przesunięcia punktu ciężkości: newralgicznym momentem jest weryfikacja transkrypcji dyplomatycznej, nie zaś tworzenie komentarza. Przyjęty podział pracy powoduje też, że transkrypcja ta przechodzi o wiele dokładniejszą weryfikację niż ma to miejsce zazwyczaj w modelu tradycyjnym. W efekcie powstaje edycja o dużym stopniu ,,wiarygodności” a uzyskane dane mają o wiele wyższą jakość. Co więcej, ponieważ dysponujemy dwoma wersjami utworu, możemy nie tylko stworzyć automatycznie komentarz, ale także wizualnie pokazać różnice pomiędzy źródłem a jego edycją wyświetlając je w partyturze cyfrowej. Najbardziej oczywistą metodą będzie np. podświetlenie lub pokolorowanie nut, które różnią się od zapisu oryginalnego w edycji. Możliwe jest też m.in. stworzenie narzędzi pozwalających wyświetlanie wariantów i różnych decyzji redaktorów lub wręcz rozwiązań alternatywnych.9
Mając na uwadze powyższe, a także model przepływu danych i pracy przedstawiony wcześniej, możemy wywnioskować, że dla każdego utworu opracowywanego w projekcie powinny powstać zasadniczo trzy główne pliki:
plik xml możliwie wiernie odzwierciedlający przekaz źródłowy,
plik krn – transkrypcja dyplomatyczna,
plik krn – edycja krytyczna.
W dyskusjach na edycjami dzieł Chopina często podnoszony jest niezwykle złożony problem oddzielenia dwu warstw partytury: (1) czystej informacji muzycznej (nazwijmy ją informacją logiczną lub po prostu danymi) i (2) warstwy graficznej (ang. layout). Problem można zilustrować na przykładzie sposobu, w jaki współczesne edytory muzyczne odróżniają łuki frazowe i artykulacyjne od łuków ligujących (łączących dwie nuty oddzielone graficznie, które jednak stanowią jedną całość – np. w przypadku gdy wartość rytmiczna nuty przekracza kreskę taktową). Przyjęło się, że łuki ligujące są bardziej płaskie od łuków artykulacyjnych. Pozwala to muzykom szybko zorientować się czy mają zagrać dwie nuty legato, czy też przetrzymać wartość rytmiczną.
Niestety omawiany problem rzadko występuje w tak prostej do rozstrzygnięcia postaci. Bardzo często są to zjawiska bardzo zniuansowane – o ile wyraźne przesunięcie oznaczenia p (piano) za nutę w sposób oczywisty oznacza, że dynamikę tego typu należy wprowadzić już po zagraniu tego konkretnego dźwięku, o tyle można dyskutować, czy umieszczenie tego znaku lekko po lewej, dokładnie pod lub nieco po prawej, ma znaczenie dla wykonawcy, czy jest tylko przyjętą przez wydawcę konwencją. Zwróćmy uwagę, że nawet we współcześnie przygotowywanych komputerowych składach nutowych, w przypadku gdy zapis jest szczególnie ,,gęsty”, oznaczenia bywają nieco przesuwane aby uniknąć nachodzenia ich na siebie.
Niniejsza instrukcja mając na celu przede wszystkim względy praktyczne, nie może być traktowana jako głos w powyższej dyskusji. Przyjęte rozwiązania mają uzasadnienie praktyczne, wynikające przede wszystkim z dążenia do zakodowania w formacie tekstowym jak najwierniejszego odzwierciedlenia źródła. Omawiany problem ma w przypadku projektu NIFC znaczenie drugorzędne, ponieważ zawsze i bez wyjątku każda transkrypcja oparta jest tylko o jedno źródło,10 którego kopia cyfrowa jest udostępniona. Możliwa jest zatem bardzo szybka weryfikacja edycji w oparciu o łatwo dostępne skany oryginału. Konkretne wskazania, które elementy zapisu nutowego uznajemy w projekcie za informację logiczną, a które za graficzną omówiono poniżej, w początkowej części rozdziału 3.
Jak wspomniano powyżej w trakcie opracowywania danej kompozycji w projekcie NIFC powstają trzy główne pliki.11 Merytorycznie rzecz biorąc zarówno plik xml jak i pierwszy plik w formacie krn powinny być transkrypcjami dyplomatycznymi, jak na poniższym schemacie (przyk. 3.1.
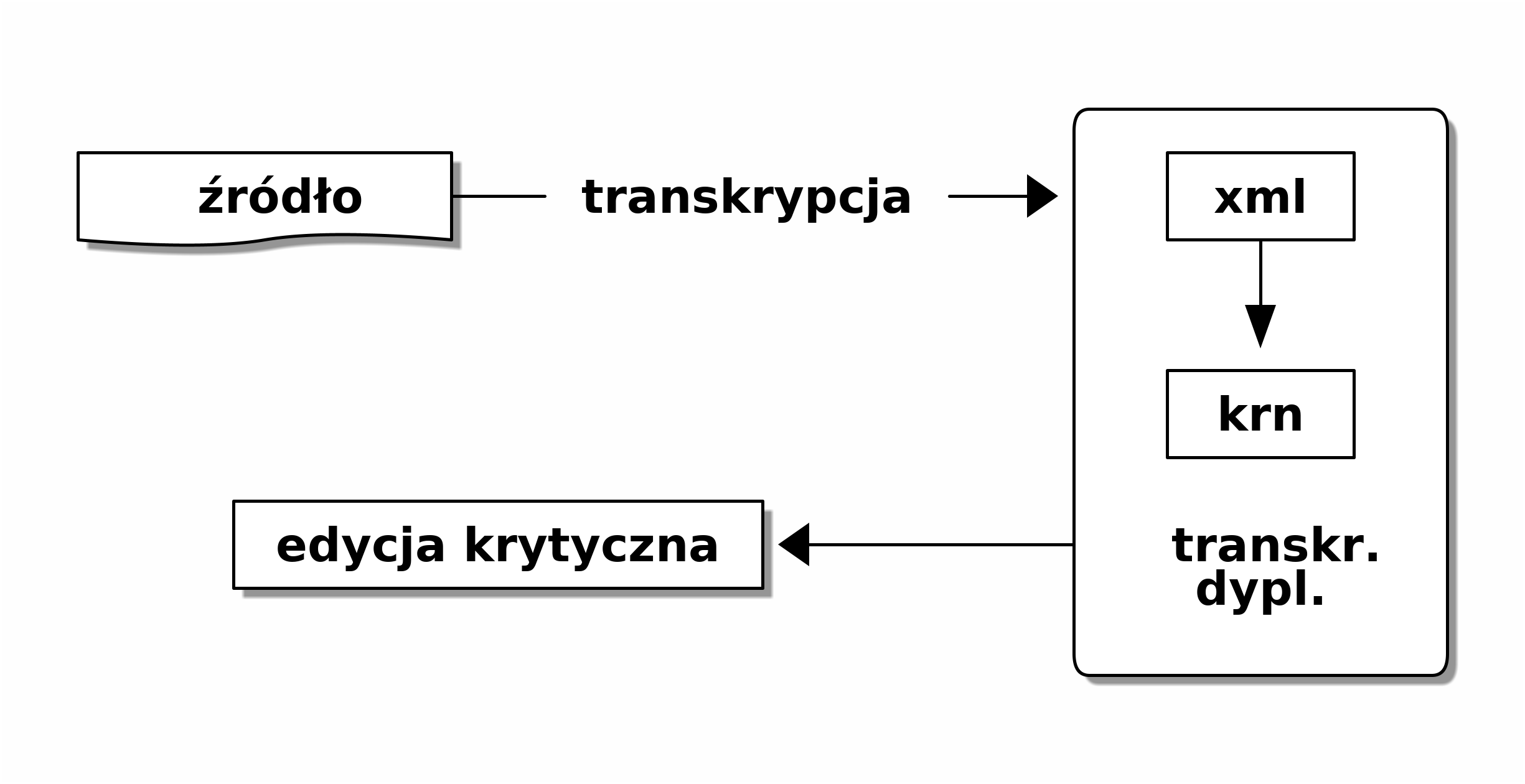
Kluczowe znaczenie ma plik krn transkrypcji dyplomatycznej. Na bazie tego pliku tworzona jest edycja krytyczna. Plik xml jest jedynie pośrednim ogniwem, jednak jego znaczenie jest niezwykle ważne i powinien być przygotowany z największą starannością. Konieczność tworzenia pliku xml wynika głównie ze względów praktycznych. Kodowanie muzyki (zwłaszcza wielogłosowej) w formacie krn jest możliwe, ale bardzo niewygodne i czasochłonne. Z tej przyczyny lepiej posłużyć się programem z interfejsem graficznym (MuseScore, Finale, Sibelius) i stworzyć plik xml, który następnie można łatwo przekonwertować do formatu xml. Następnie plik w formacie krn jest korygowany zgodnie z zapisem źródłowym. Warto odpowiedzieć na pytanie, dlaczego to uzgodnienie ze źródłem nie może być w całości wykonane w edytorze nutowym, chociaż transkrypcja xml również ma spełniać kryteria dyplomatycznej?
Każdy ze wspomnianych edytorów nutowych tworzy plik w formacie obsługiwanym tylko przez siebie. Nie można pliku mscz (plik MuseScore) otworzyć w Finale, ani odwrotnie, pliku musx (plik Finale) w MuseScore czy Sibeliusie. Wynika to z faktu, że są to programy typu WYSIWYG,12 czyli takie, w których to, co widzimy na ekranie jest tym, co zobaczymy na wydruku. Problematyczne jest to, że wszelkie poprawki graficzne (np. przesunięcia oznaczeń, zmiany czcionek itp.) w każdym z tych programów zapisywane są inaczej. Co więcej, programy te (zwłaszcza Finale) mają bardzo dużo domyślnych ustawień, które wymuszają np. takie a nie inne rozmieszczenie nut. Może się zdarzyć, że żmudna praca redaktora, który poprzestawiał znaki w partyturze pójdzie na marne, kiedy ten sam plik otworzymy choćby za pomocą innej wersji tego samego programu. Ponadto należy pamiętać, że nie wszystkie informacje (zwłaszcza o warstwie graficznej partytury) są eksportowane do formatu xml.
Kolejnym problemem jest fakt, że we wspomnianych programach w zasadzie nie da się zapisać bardzo wielu informacji pozwalających odtworzyć zapis źródłowy. Można np. ukryć poszczególne nuty, jeśli nie ma ich w źródle (co bywa konieczne kiedy np. musimy dopełnić wartościami rytmicznymi miarę taktu), ale w istocie sprowadza się do jedynie do operacji czysto graficznych. Z tak przygotowanymi plikami nie można wiele zrobić, a już z pewnością nie da się na ich analizować, badać czy tworzyć na ich podstawie wyszukiwarek etc. Jak wspomniano w programach WYSIWYG to co widzimy na ekranie stanowi efekt końcowy. W jakim znaczeniu ta pozorna korzyść stanowi problem? Otóż typowym zabiegiem dokonywanym przez autorów składów nutowych jest ich ,,upiększanie” poprzez ręczne przesuwanie elementów graficznych. Dla większości takich elementów, jak oznaczenia dynamiczne, artykulacyjne, ozdobniki etc. stosowane jest zakotwiczenie znaku do określonej nuty. Jednak ręczne przesunięcie oznaczenia niezwykle często skutkuje jedynie graficznym przesunięciem znaku, przy jednoczesnym pozostawieniu niewłaściwego zakotwiczenia. Zjawisko to ilustruje dobrze przykład zapisu nutowego w programie Finale (zob. przyk. 3.2).

Program za pomocą niebieskiej linii przerywanej wyświetla informację o zakotwiczeniu oznaczenia (czego nie widać na późniejszym wydruku), które z muzycznego punktu widzenia (jeśli sugerować się jedynie warstwą graficzną) przynależy raczej do drugiej szesnastki i to w innym głosie. Tego typu niepożądanej niejednoznaczności zapisu łatwo uniknąć w większości formatów otwartych, a w sporej części z nich (m.in. w Humdrum) jest ona wręcz niemożliwa z uwagi na rygorystyczną syntaksę. Dodatkowe problemy wynikające z faktu wykonania transkrypcji w formacie zamkniętym wiążą się ze specyficznymi cechami notacji muzycznej. Zastosowanie nietypowych czcionek, ręczne przesuwanie systemów na stronie, ukrywanie elementów w celu osiągnięcia pożądanego efektu graficznego – te wszystkie zabiegi powodują, że tak przygotowany skład w zasadzie nie może być wykorzystany w innym celu niż do sporządzenia wydruku. W aspekcie funkcjonalnym zatem, plik tego typu jest niemal równoważny transkrypcji wykonanej ręcznie na papierze nutowym.
Inaczej jest w programach i formatach typu WYMIWYG,13 czyli dostajesz to, co masz na myśli. W formacie krn każde oznaczenie zawsze jest przypisane bądź do konkretnej nuty, bądź precyzyjnie umieszczone za pomocą tzw. znaczników czasowych wyrażonych w wartościach rytmicznych.14 Ponieważ informacja ta jest zapisana w tekście, niezależnie od tego jakim programem otworzymy plik, będzie ona zawsze w tym samym miejscu. Ponadto – co szczególnie ważne – ma wartość informacji logicznej a nie graficznej. Innymi słowy można dzięki takiemu zapisowi badać tak specyficzne problemy, jak np. porównanie miejsc w jakich różni wydawcy umieszczali znaki dynamiczne w analogicznych wydaniach.
Obecnie możemy przejść do konkretnych wskazówek dotyczących sposobu tworzenia transkrypcji. Dla każdego z rodzajów transkrypcji i formatów plików zasady te będą się nieco różnić, z uwagi na wspomniane powyżej ograniczenia oprogramowania.
Plik xml w projekcie NIFC może powstać na dwa sposoby:
wykonanie ręcznej transkrypcji w edytorze nutowym,
wykonanie OMR druku muzycznego.
W obydwu przypadkach plik xml wyeksportowany z programu OMR lub Finale bądź Sibeliusa należy otworzyć w darmowym programie MuseScore w najnowszej wersji, i dopiero ten plik przesłać jako zakończoną transkrypcję. Jeżeli transkrypcja jest wykonywana ręcznie, należy rozpocząć pracę od otwarcia pustego pliku xml przygotowanego przez NIFC, uzupełnić wymagane dane (będą w pliku), wykonać transkrypcję.
Każdy plik xml opracowywany w ramach projektu zawiera sekcję metadanych o stałym zestawie pól, które prezentuje tabela 3.1. Edytorzy plików xml uzupełniają pola @@ENC i @@END w sekcji metadanych. Te dane będą też zawarte w pliku krn po konwersji.
| POLE | ZNACZENIE |
|---|---|
| @id: | Tymczasowe ID |
| @COM: | Nazwisko i imię kompozytora |
| @OTL: | Tytuł źródła |
| @PDT: | Data powstania źródła |
| @SMS-siglum: | Siglum RISM miejsca przechowywania źródła |
| @SMS-shelfmark: | Sygnatura źródła |
| @SMS-variant: | Wariant źródłowy, na którym oparta jest edycja |
| @SMS-altvar: | Alternatywny wariant źródłowy |
| @NIFC-rismID: | ID kompozycji w bazie RISM |
| @URL-scan: | Link do skanów źródła |
| @ONB-nifc: | Uwagi dotyczące źródła |
| @@ENC : | Imię i nazwisko edytora pliku xml |
| @@END: | Data ukończenia edycji w formacie rrrr-mm-dd |
Wyróżnia się dwa rodzaje lekcji:
lectio ante correcturam (lekcja przed korektą),
lectio post correcturam (lekcja po korekcie).
Źródła rękopiśmienne a także starsze druki muzyczne obfitują w liczne korekty oryginalnego zapisu. Poprawki tego typu były nanoszone przez autora, który mógł zmienić zamysł lub skorygować pomyłkę, kopistę, który chciał poprawić swój błąd, muzyka, który wykonując partię uznał, że wymaga ona korekty. Odczytując źródła często należy podejmować decyzje, który zapis powinien zostać uznany za właściwy. Przygotowując plik xml należy kierować się następującymi zasadami.
Dla druków muzycznych należy zawsze przyjąć lekcję przed korektą. Wszelkie oznaczenia, dopiski, dodatki rękopiśmienne, należy uznać za wtórne i nie umieszczać ich w transkrypcji nawet, jeśli stanowią korektę oczywistych błędów. Jeżeli oryginalny zapis drukowany jest niemożliwy do odczytania z uwagi na defekt (np. brakujący fragment karty) a został uzupełniony rękopiśmiennie, należy taki zapis umieścić w transkrypcji oznaczając jego wystąpienie komentarzem tekstowym (zob. przyk. 3.3).
W przypadku rękopisów muzycznych należy przyjąć generalną zasadę mówiącą, że lekcją właściwą jest lekcja po korekcie głównego skryptora. Dla dopisków późniejszych (pisanych innym narzędziem, innym atramentem, ołówkiem, inną ręką) przyjmuje się, że obowiązuje lekcja przed korektą. W Aneksie (zob. 8) przedstawione zostały przykłady ilustrujące najczęściej spotykane w źródłach sytuacje. W przypadkach wątpliwych i trudnych do rozstrzygnięcia należy skontaktować się z koordynatorem projektu.
Pełne nazwy głosów w edycji dyplomatycznej powinny być wierną transkrypcją zapisu źródłowego. Jedynym odstępstwem od tej reguły jest rozwinięcie abrewiatur słownych. Jeśli wpisana w źródle nazwa głosu jest błędna, na przykład podaje błędną tonację instrumentu transponującego, to do pierwszego dźwięku tej partii dodać należy notatkę opisującą tę sytuację. Jeśli w źródle nie występuje nazwa partii, ale na podstawie kontekstu można ze stuprocentową pewnością wywnioskować, jaki instrument realizuje daną partię, właściwą nazwę należy zakodować w źródle w nawiasie kwadratowym.
W przypadku zapisu w głosach skrótowe nazwy instrumentów nie pojawiają się nigdy. Mimo to, dla ułatwienia nawigacji w edycji należy dodać także nazwę skrótową. Skrótowe nazwy powinny być zgodne z wytycznymi RISM, dostępnymi pod poniższym linkiem. W źródłach partyturowych, jeśli skrót nazwy został użyty, należy uwzględnić go zgodnie ze źródłem. Jeśli został pominięty, zastosować należy ujednolicone skróty zgodne z RISM.
Powinny być zawsze zapisane w oryginalnej postaci. Jeżeli partia zapisana jest w kluczu C1, zapisujemy ją właśnie w tym kluczu – nie zamieniamy kluczy na współczesne (np. zostawiamy klucz tenorowy nie zamieniając na wiolinowy z przenośnikiem oktawowym).
Wyjątkiem od tej zasady jest zmiana klucza na błędny, lub brak
koniecznej z punktu widzenia zmiany klucza w źródle. W takiej sytuacji w
transkrypcji do pliku MusicXML należy wprowadzić właściwą/niezbędną
zmianę klucza i opatrzeć ją odpowiednią notatką typu
problem. W przeciwnym razie wysokości dźwięków zanotowane
według źródłowych kluczy będą całkowicie niepoprawne, a edycja nie
będzie spełniać swoich podstawowych funkcji.
Wpisujemy jak oryginale, nawet jeśli są nieadekwatne.15 Problemem może być sytuacja, w której specyficznie zanotowano znaki – np. powtórzono ten sam krzyżyk w dwu oktawach (fis1–cis2–fis2). W takiej sytuacji wpisujemy tonację zgodnie z zasadami współczesnej ortografii dodając komentarz tekstowy przy pierwszym takcie w miejscu, w którym występuje problem.
Transpozycja instrumentu musi być uwzględniona w edycji – kluczowe są w tym przypadku brzmiące wysokości dźwięków. Przy sporządzaniu edycji do formatu MusicXML przy pomocy oprogramowania MuseScore nie powinno to nastręczać problemów - we właściwościach partii należy ustawić odpowiednią transpozycję, dzięki czemu dźwięki będą się wyświetlać zgodnie ze źródłem, a jednocześnie będą współbrzmieć z pozostałymi głosami kompozycji. W sytuacji, w której transpozycja instrumentu zmienia się w trakcie trwania utworu, w transrypcji należy zmienić instrument w odpowiednim miejscu edycji, korzystając z narzędzia Change Instrument Text. Opis, jak należy używać tego narzędzia można znaleźć pod poniższym linkiem16.
Choć divisi i colla parte to zasadniczo dwie różne sytuacje, w formacie XML należy je przetranskrybować w podobny sposób.
W przypadku, gdy divisi w źródle zanotowane jest na jednej pięciolini, kodowanie w żaden sposób się nie zmienia - dźwięki wyższego instrumentu koduje się w warstwie pierwszej, a niższego w drugiej. Inaczej należy postępować, gdy partia instrumentu w większości źródła zapisana jest na jednej pięciolinii, ale we fragmentach rozdziela się na dwie pięciolinie. W takim przypadku instrument powinien być zakodowany na dwóch pięcioliniach od początku części. We fragmentach, w których w źródle występuje tylko jedna pięciolinia, obie partie powinny być identyczne, przy czym w partii niższego instrumentu wszystkie elementy powinny zostać ukryte. Jedynie we fragmentach, w których w źródle następuje podział na dwie pięciolinie partie instrumentów mogą się różnić, tylko w tym miejscu dźwięki drugiego głosu będą też widoczne (por. 3.4 i 3.5).


Analogicznie rozwiązać należy kwestię zapisu colla parte - jeśli w źródle pojawia się sugestia, że jeden instrument powinien grać te same dźwięki co drugi (np. col Basso), obie partie powinny być zakodowane identycznie, przy czym dźwięki w instrumencie, w którym znajduje się odsyłacz należy ukryć.
Należy je wpisać zgodnie z zapisem oryginalnym. Jeśli brak metrum w
źródle, należy oznaczyć to komentarzem tekstowym
problem: brak metrum.
Klamry czyli akolady wpisujemy jak w źródle, o ile mamy do czynienia z zapisem partyturowym. Jeśli tworzymy skład z ksiąg głosowych, głosy układamy w odpowiedniej kolejności (por. Aneks, tabela 8.1), a grupy łączymy akoladą.
W plikach MusicXML pauzy wielotaktowe powinny zostać rozdzielone, tak, aby wykorzystane wartości rytmiczne nie przekraczały ram taktu. Jeśli nad pauzą wielotatkową pojawia się dodatkowo numer wskazujący, ile taktów obejmuje pauza, należy go wpisać do transkrypcji jako notatka tekstowa, dodana do pierwszej pauzy z grupy.
Zapisujemy dokładnie jak w źródle. W starszych źródłach bardzo często występują tzw. znaki przypominające – należy je zawsze skrupulatnie wypisać (w edytorach nutowych oznacza to ,,wymuszenie” wyświetlania znaku). Nie dodajemy żadnych akcydencji nawet gdy ich brak jest ewidentnym błędem.
Zwłaszcza w starszych źródłach można spotkać się z zapisywaniem
kasownika za pomocą krzyżyka – w takiej sytuacji w edycji należy
wykorzystać znak zgodny ze współczesną ortografią muzyczną. Dżwięk
należy też opatrzeć notatką, informującą o znaku akcydencyjnym
zastosowanym w źródle w brzmieniu !LO:N:acc=[-n#], gdzie
- oznacza bemol, n – kasownik, a
# – krzyżyk.
Ponieważ edytory nutowe automatycznie poprawiają chromatykę, należy poświęcić szczególną uwagę, aby wszystkie znaki zostały wpisane jak w źródle.
Artykulacja powinna być wpisana jak w źródle. Należy pozostawić
oznaczenia w takiej postaci, a jakiej zostały wpisane w źródle. Dotyczy
to w szczególności kreski pionowej, która może oznaczać – w zależności
od kontekstu – détaché, tasto solo, lub
staccatissimo. Kreski tej nie należy zamieniać na kropki
(staccato) lub kliny (staccatissimo) – w zamian, do
nuty, przy której w źródle pojawia się takie oznaczenie, należy przypiąć
notatkę tekstową |.
Nie należy dodawać żadnych oznaczeń, których nie ma w źródle. Nie należy przesuwać oznaczeń nawet, jeśli w źródle są wpisane niedokładnie (nie nad lub pod nutą, ale nieco przesunięte). Należy natomiast zachować układ wertykalny – tzn. jeśli dane oznaczenie jest wpisane pod nutą, powinno tak właśnie zostać wpisane (nie należy przeciągać ręcznie oznaczenia, tylko użyć odpowiedniego dla danego edytora sposobu wprowadzania).
Powinny być wpisane jak w źródle. W szczególności dotyczy to oznaczenia t, które w starszych rękopisach może oznaczać trillo i nie należy go zamieniać na tr.
Należy wpisać jak w źródle nawet, jeśli oznaczałoby to zapis niepoprawny. Należy zachować wartości rytmiczne przednutek jak w źródle oraz zachować rozróżnienie pomiędzy acciacatura i appoggiatura używając przekreślenia lub nie. Jeżeli program nie pozwala na zapisanie przednuty (lub grupy) w takiej postaci, jak w źródle, należy odnotować to komentarzem tekstowym.
Wyróżniamy dwa rodzaje flażoletów - naturalne i sztuczne. Flażolety naturalne najczęściej notuje się przez dodanie oznaczenia w formie kółka nad nutą. Tak też należy postępować w przypadku edycji do formatu MusicXML.
Notacja flażoletów sztucznych jest nieco bardziej skomplikowana. Może się składać z trzechlub dwóch dźwięków (por. 3.6). Co więcej nie da się jej zastosować w programie MuseScore, tak żeby przeniosła się do formatu Humdrum. Dlatego też w przypadku flażoletów, najlepiej zakodować wysokości dźwięków, oznaczonych w źródle o odpowiedniej wartości rytmicznej. Nie należy przy tym zmieniać główki nut na romb, gdyż i tak informacja ta nie przejdzie do formatu Humdrum.

Jeśli na końcu linii w źródle pojawia się kustosz (łac.
custos), w transkrypcji dyplomatycznej do nuty, po której
występuje należy dodać notatkę **custos:[wysokość dźwięku].
Wysokość dźwięku powinna być zakodowana w formacie Humdrum (por. 2.2), na przyklad
**custos:G.
Rodzaj notacji a dokładniej kształt nut należy uwspółcześnić. Jeżeli utwór został zapisany notacją menzuralną lub quasi-menzuralną, nie stosujemy osobnych czcionek w tej postaci. W przypadku pauz wielotaktowych (np. o długości brevis) rozpisujemy je odpowiednio do zastosowanego metrum i w ramach taktów.
Jeżeli w utworze pojawia się notacja chorałowa (nota
quadrata, metzeńska lub in.) zapisujemy wartości w równych
ćwierćnutach oznaczając ligatury za pomocą komentarzy tekstowych: nad
pierwszą nutą ligatury umieszczamy komentarz *lig, zaś nad
ostatnią nutą ligatury komentarz **Xlig.
Łuki frazowe i artykulacyjne należy wpisać jak w źródle pamiętając o ich odpowiednim ,,zakotwiczeniu”. Każdy łuk powinien być przyczepiony do dwu nut – nie należy ręcznie przeciągać łuku. Należy zachować układ wertykalny – dotyczy to umiejscowienia łuku (nad lub pod nutami) oraz kierunku jego wygięcia. Powyższe wskazówki odnoszą się także do łuków ligujących (łączących wartości rytmiczne).
Łuki łączące nuty w partiach wokalnych, za pomocą których oznaczono melizmaty, należy wpisać zgodnie z zapisem źródłowym.
Powinny zostać w pliku xml utworzone automatycznie przez program. Taki ich układ zgodny z metrum należy pozostawić. Nie należy ukrywać kresek taktowych ani stosować innych oznaczeń w ich miejsce. Należy stosować wyłącznie pojedynczą podwójną lub końcową, a także ich warianty wynikające z oznaczeń repetycji. W przypadku oznaczenia metrum w notacji menzuralnej stosujemy kreski taktowe w odległości jednej brevis.
Mogą być traktowane na dwa sposoby. Jeśli plik xml jest tworzony bądź
edytowany w programie MuseScore, można zastosować graficzne oznaczenia
tremolo i tremolando - zostaną one poprawnie
przekonwertowane do formatu Humdrum. Jeśli plik jest opracowywany w
innym programie do edycji nut, lub jeśli nie ma możliwości zapisania
niestandardowego zapisu źródłowego w programie MuseScore,
tremola i tremolanda powinny zostać rozpisane.
Dźwięki, zapisane w źródle skrótowo należy w tej sytuacji połączyć
wspólną belką. Pierwszy dźwięk fragmentu zapisanego skrótowo należy
opatrzyć notatką tekstową *tremolo, ostatni zaś notatką
**Xtremolo. Możliwe sposoby zakodowania tremolo i
tremolando prezentuje przykład 3.7.

Należy przy tym zwrócić uwagę na często niejednoznaczne zapisy dające się interpretować w różny sposób. W przypadku wątpliwości co do sposobu rozwiązania abrewiacji, należy dodać komentarz tekstowy, który pozwoli zwrócić uwagę redaktorowi pliku krn na problem.
Należy wpisać w pisowni oryginalnej, zachowując także wszelkie błędy pisowni oraz cechy specyficzne (w tym znaki diakrytyczne). Sposób podpisania wielu zwrotek tekstu zależy od formatu pliku i rodzaju transkrypcji.
Czasem w zapisie kompozycji pojawiają się kreseczki, umieszczone między nutami, lub na dole pięciolinii, które wskazują, gdzie kończą się słowa tekstu słownego i jak należy je podłożyć pod nutami (por. 3.8).
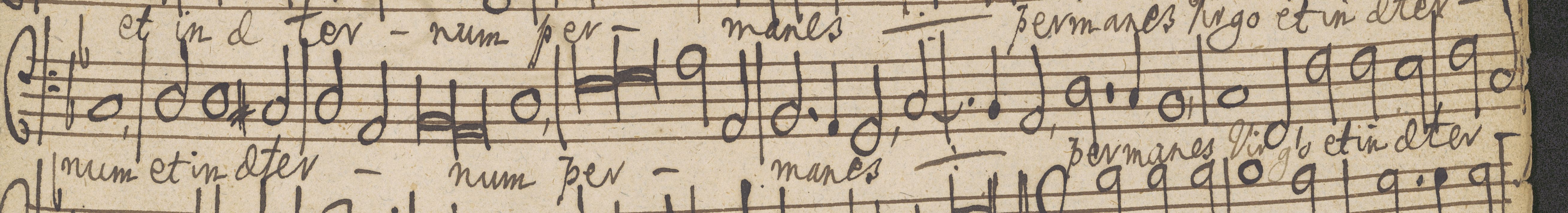
W toku projektu przyjęto, że tego typu kreski w transkrypcji do formatu MusicXML należy przetranskrybować jako oddechy.
Szczegółowo zagadnienie transkrypcji tekstów słownych omówiono w rozdziale 6.
Można podzielić na trzy grupy:
Oznaczenia graficzne ( )
)
Oznaczenia skrótowe (na przykład f, mp, sfz)
Oznaczenia tekstowe (na przykład cresc., diminuendo)
Oznaczenia graficzne należy dodać za pomocą narzędzia linii w oprogramowaniu MuseScore. Należy zadbać o to, by zakotwiczenie początku i końca znaku graficznego pokrywało się z graficznym wyświetlaniem.
Oznaczenia skrótowe należy zakodować w MuseScore za pomocą narzędzi z palety Dynamika. W źródłach oznaczenia skrótowe mogą przybierać formy odmienne od dzisiejszech – f może być zapisane jako fo: lub for, p jako p:, pia itp. Każdy z wariantów należy w takiej sytuacji uwspółcześnić (f: f).
Oznaczenia w formie odmiennej od współczesnej należy dodatkowo opisać
komentarzem tekstowym. Można to zrobić globalnym komentarzem przy
pierwszym pojawieniu się niestandardowego oznaczenia w danym jeśli taka
forma stosowana jest konsekwentnie w całym utworze/części/głosie.
Notatka powinna przybrać formę zbliżoną do
problem:w źródle zawsze f[orte] = for.. Komentarz globalny
można też wykorzystać gdy w źródle oznaczenia stosowane są
niekonsekwentnie, ale przeważa jedna forma notacji. W takiej sytuacji
każde odstępstwo należy odnotować komentarzem.
Oznaczenia tekstowe w edytorach nutowych kodowane są przeważnie jako tekst pięciolinii. Jednak w formacie Humdrum – do którego zostaną przekonwertowane pliki xml – tekstowe oznaczenia koduje się jako ten sam typ danych co oznaczenia skrótowe i graficzne. Aby zachować spójność danych, tekstowe oznaczenia źródłowe należy zakodować jako oznacznie graficzne, o czasie trwania jednego dźwięku. Tego typu oznaczenie należy wprowadzić milcząco - odpowiedzialność za poprawne zakodowanie go w formacie Humdrum spada na edytorów plików krn.
Niezależnie od typu oznacenia dynamicznego należy zachować jego położenie w układzie wertykalnym. Nie należy dodawać żadnych oznaczeń dynamicznych, których nie ma w źródle. Należy zwrócić szczególną uwagę na zakotwiczenie elementów do odpowiednich dźwięków.
W źródłach repetycje mogą być zapisane na wiele różnych sposobów - za
pomocą kresek taktowych, oznaczeń tekstowych lub symbolicznych (np.
Dal  al Fine.), czy też oznaczeń graficznych na pięciolinii (np.
al Fine.), czy też oznaczeń graficznych na pięciolinii (np.
 ). Każdy z
typów notacji repetycji wymaga odmiennego traktowania.
). Każdy z
typów notacji repetycji wymaga odmiennego traktowania.
Jeśli źródło to partytura, repetycje obejmujące wszystkie głosy –
zarówno te zapisane za pomocą kresek taktowych, jak i te słowne czy
symboliczne – powinny zostać oznaczone jak w źródle i nie należy ich
rozpisywać. Oznaczenia graficzne segno () oraz
coda ( ) można zakodować słownie odpowiednio jako
) można zakodować słownie odpowiednio jako
[segno] i [coda].
Podobne rozwiązanie można przyjąć w przypadku kompozycji zapisanej w głosach, w której oznaczenia repetycji występują w tym samym momencie w każdym z głosów.
W przypadkach, gdy repetycja dotyczy tylko jednego lub części głosów,
repetycję taką należy rozpisać, wszystkie dźwięki ukryć, a do pierwszego
dźwięku rozpisanego fragmentu dodać należy notatkę
problem:fragment oznaczony znakiem repetycji.
Wielokrotne powtórzenia krótkich fragmentów również należy rozpisać.
Do pierwszej nuty powtórzonego fragmentu należy dodać notatkę
*rep, a do ostatniej **Xrep. Takie rozwiązanie
ilustruje przykład 3.9.

Łamania systemów i stron należy zachować zgodnie ze źródłem – w programie MuseScore jest narzędzie pozwalające oznaczyć miejsce łamania systemu i strony. Przed przesłaniem pliku xml należy w MuseScore oznaczyć te miejsca. Dotyczy to oczywiście zapisów partyturowych – w przypadku ksiąg głosowych nie należy umieszczać takich oznaczeń, a jeśli po otwarciu pliku xml w programie MuseScore się pojawią, należy je usunąć.17
Belkowanie (ang. beaming) nut należy wpisać jak w źródle nawet, jeśli jest ono niezgodne z zapisanym metrum i współczesnymi zasadami ortografii muzycznej. Nie należy uzgadniać belkowania w partiach wokalnych z sylabami tekstu słownego, tylko pozostawić jak w źródle.
W sytuacji, miejsce belki w stosunku do nut nią objętych się zmienia,
do pierwszej nuty grupy należy dodać notatkę
problem:mixed beam.
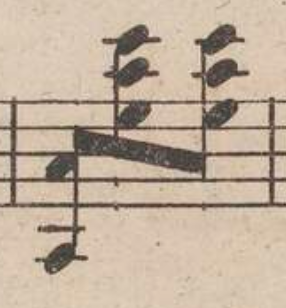
Oznaczenia bc będą uzupełniane w plikach krn, dlatego nie należy ich wpisywać w transkrypcji xml.
Poniżej przedstawiono (niepełną) listę problemów, jakie najczęściej można spotkać podczas tworzenia transkrypcji. Proponowana lista rozwiązań dotyczy wyłącznie składów w plikach xml.
Wysokości dźwięków powinny być zakodowane tak jak w źródle, nawet
jeśli są one wpisane ewidentnie błędnie. Ewidentne błędy należy oznaczyć
notatką typu SIC.
System SIC został stworzony na potrzeby projektu Dziedzictwo Muzyki Polskiej w otwartym dostępie18. Za jego pomocą zakodować można:
informację o tym, że błąd/niekonsekwencja zamieszczona w transkrypcji to rzeczywiste odwzorowanie źrodła,
jaki dźwięk znajduje się w źródle
(o=[oryginalny dźwięk]),
jaki dźwięk powinien być wpisany w źródle
(s=[właściwy dźwięk]),
notatkę tekstową, opisującą sytuację w źródle
(t=[komentarz]),
informację o tym, czy w partyturze graficznej powinien zostać
wyświetlony znacznik, wskazujący na obecność notatki SIC
(v)
W edycjach dyplomatycznych notatka SIC powinna zawierać informację o
tym, jaki dźwięk powinien być wstawiony w miejsce błędnie wpisanego
dźwięku w źródle. Notatka ta ma formę
!LO:SIC:s=[właściwy dźwięk]:v, przy czym
[właściwy dźwięk] należy każdorazowo zastąpić odpowiednim
kodowaniem w formacie Humdrum (por. tabele 2.1, 2.2 i 2.3). Istotne
jest, żeby kodowanie dźwięku w parametrze s= było pełne, to
znaczy zawierało wartość rytmiczną i wysokość wraz ze znakami
chromatycznymi i artykulację. Jeśli zachodzi potrzeba dodatkowego,
tekstowego doprecyzowania, do notatki dodać można parametr
:t= oraz słowny opis problemu
(SIC:s=4f:t=lub 4a). Jeśli błędnie wpisano jeden z dźwięków
akordu, w parametrze s= należy wpisać wszystkie dwięki
akordu zaczynając od góry, np: !LO:SIC:s=4cc 4a- 4f. Sposób
oznaczania błędów w źródle za pomocą notatek SIC ilustruje przykład 3.11.

SICDość często zdarza się, że z uwagi na błąd skryptora miara taktu nie
jest dopełniona, tzn. w takcie jest za mało wartości rytmicznych w
stosunku do metrum. Problem może wynikać np. z przypadkowego połączenia
dwu ćwierćnut belką (powstają dwie ósemki), pominięcia nuty,
nieprecyzyjnego zapisu. W takiej sytuacji należy zakodować właściwą – z
punktu widzenia logiki przebiegu muzycznego – wartość rytmiczną, tak by
miara taktu była dopełniona. Zmiany takie powinny być uzasadnione – np.
na podstawie analizy analogicznych fragmentów, w przypadku stwierdzenia
oczywistej pomyłki etc. Fakt wprowadzenia zmiany należy oznaczyć
komentarzem tekstowym !LO:N:vis=[wartość rytmiczna], przy
czym [wartość rytmiczna], powinna być zastąpiona
symbolicznym zapisem właściwego rytmu w formacie Humdrum (według zasad
przedstawionych w tabeli 2.1). Właściwą transkrypcję taktów o
niepełnej mierze ilustruje przykład 3.12.
Przepełniona miara taktu jest sytuacją analogiczna do poprzedniej i
problem ten należy rozwiązać podobnie (zob. przyk. 3.13).


Uwaga – należy dokładnie sprawdzić, czy niezgodność metryczna nie wynika z zastosowania grup niemiarowych, które nie zostały oznaczone w źródle. Zdarza się bowiem, że triole i in. grupy niemiarowe zostały zapisane bez oznaczenia ich stosowną cyfrą (np. 3 dla trioli), mogły też zostać oznaczone jedynie łukiem lub w ogóle. Zwykle w takiej sytuacji pomocne jest porównanie z pozostałymi partiami (w przypadku zapisu w księgach głosowych).
Niejednoznaczność zapisu to jeden z najczęściej spotykanych problemów. Zwykle dotyczy wysokości nut (nie jest jasne, czy nuta jest w polu czy na linii) lub wartości rytmicznej. Najczęściej problem ten jest stosunkowo łatwy do rozwiązania, bowiem logika przebiegu muzycznego podpowiada właściwy wybór. Jeśli jednak nie można jednoznacznie stwierdzić, jakie rozwiązanie jest właściwe, należy przyjąć jedną z możliwych opcji i dodać komentarz tekstowy.19
W przypadku źródeł zapisanych nie w układzie partyturowym a tzw.
księgach głosowych (gdzie każdy z głosów kompozycji zanotowany jest
osobno) dość często zdarza się, że w wybranych głosach z uwagi na
pomyłkę skryptora brak jednego lub więcej taktów utworu. W bardziej
kłopotliwych przypadkach problem ten występuje w więcej niż jednym z
głosów, co może prowadzić do sytuacji, kiedy po wykonaniu transkrypcji
partie poszczególnych głosów nie kończą się jednocześnie. Aby rozwiązać
ten problem, należy w pierwszej kolejności określić właściwą liczbę
taktów utworu20 a następnie w stosownych
miejscach uzupełnić brakujące fragmenty. Dodane takty należy
pozostawić puste (wypełniając ukrytymi pauzami) oraz oznaczyć je za
pomocą komentarza tekstowego w postaci np.:
problem: brak taktów nr 1-5 (zob. przyk. 3.14).
Równie często spotykanym błędem skryptorów jest sytuacja odwrotna – w
wyniku pomyłki fragmenty kompozycji zostają zbędnie powtórzone. Problem
należy rozwiązać nieco inaczej. Zbędne fragmenty w danym głosie należy
wpisać do partytury i oznaczyć je komentarzem tekstowym, np.:
problem: zbędne powtórzenie taktów nr 1-5,
problem: niepotrzebnie powtórzony fragment itp. W efekcie w
głosach poprawnie wpisanych powstaną luki. Luki te należy pozostawić
puste (wypełniając ukrytymi pauzami) oraz oznaczyć je komentarzem
tekstowym np.: problem:zbędne powtórzenie taktów w C..
Sytuację taką ilustruje przykład 3.15.21


Fragmenty pominięte w żródle, ale dopisane później przez tego samego
skryptora w innym miejscu źródła (wolna strona, dorysowana pięciolinia
na dole itp.) w transkrypcji należy umieścić w miejscu, na które
wskazuje logika przebiegu muzycznego, a nie wygląd źródła. Do pierwszego
dźwięku wpisanego w innym miejscu fragmentu należy dodać notatkę
tekstową typu problem, opisującą zwięźle sytuację, na
przykład problem=t. 102-104 wpisane na dole strony. Jeśli w
źródle umieszczono dodatkowe oznaczenia nawigacyjne typu Vi=,
=de, re=, =tro, należy je zachować w
transkrypcji w odpowiednich miejscach.
Nieco inaczej należy się zachować w sytuacji, gdy uzupełnienie pochodzi od późniejszego kopisty i jest de facto redakcją źródła - na przykład zastąpieniem odcinka pauz nowym materiałem muzycznym. W takim przypadku obowiązują zasady, opisane w podrozdziale Lekcja (por. 3.1.1) - za wersję główną uznajemy w tym przypadku kształt źródła utrwalony przez głównego skryptora. Drugą wersję z uzupełnieniami stworzy edytor pliku krn22.
Dość często łuki frazowe lub artykulacyjne zapisane są w sposób niejednoznaczny, niepozwalający ,,zakotwiczyć” je w sposób nie budzący wątpliwości. Problem ten może dotyczyć także oznaczeń artykulacyjnych, dynamicznych, ozdobników i in. W transkrypcji powinna obowiązywać naczelna zasada nie dodawania jakichkolwiek oznaczeń nawet, jeśli miałyby stanowić ujednolicenie w stosunku do partii analogicznej do właśnie wpisywanej (np. uzupełnienie brakujących oznaczeń w partii pierwszych skrzypiec, na podstawie partii drugich skrzypiec lub podobnie). Zasada powyższa dotyczy także niespójności oznaczeń także w ramach jednego głosu – nawet jeśli jakaś figura powtarzana jest wielokrotnie i tylko w jednym przypadku brak oznaczenia, nie należy go dodawać.
W przypadku, gdy w danym głosie dane oznaczenie zostało wpisane
niejednoznacznie, należy przyjąć wersję najbardziej prawdopodobną (na
podstawie analogicznych do niego przypadków – np. powtarzanego motywu,
frazy itp.). Jeżeli brak jakichkolwiek punktów odniesienia, należy
przyjąć jedno z możliwych rozwiązań i oznaczyć miejsce komentarzem
słownym – np. w postaci
problem: zapis łuku niejednoznaczny.
Komentarz tekstowy należy umieścić w partyturze zakotwiczając go do
obiektu, do którego się odnosi. Jeżeli nie można zakotwiczyć tekstu do
wybranego obiektu, należy go zakotwiczyć do pierwszej nuty następującej
po tym obiekcie. Komentarz powinien mieć następującą strukturę:
problem: opis słowny.
W programie MuseScore należy kliknąć odpowiednią nutę, następnie
nacisnąć kombinację klawiszy ctrl+t i wpisać tekst –
zostanie on automatycznie zakotwiczony do wybranej nuty. W programie
Finale należy użyć narzędzia tekstowego (Text Tool) oraz
zaznaczyć opcję zakotwiczenia tekstu do taktu (Assign New Text to
Measure). W programie Sibelius zalecane jest użycie narzędzia
Plain text, choć komentarze tekstowe wprowadzone jako
Expression i Technique także zostaną poprawnie
zapisane w formacie xml.
Zasady odczytywania źródeł dla druków muzycznych w przypadku transkrypcji w formacie Humdrum są analogiczne do zasad dla plików xml (por. 3.1).
Format Humdrum umożliwia stosunkowo łatwe kodowanie kilku wersji tego
samego utworu, a także porównywanie wariantów kompozycji, dlatego w
przypadku rękopisów muzycznych każda lekcja – przed
korektą, po korekcie, a także wersje pośrednie – powinny być zakodowane
jako osobne pliki. Plikiem głównym powinna być lekcja przed wszelkimi
korektami. Kolejne wersje powinny być tworzone na podstawie pliku
głównego. Poprawki głównego skryptora źródła powinny być zakodowane w
nowym pliku krn, którego nazwa powinna być rozbudowana o sufiks
-pc0, np.:
pl-cz--iii-506_neumann-wawrzyniec-vesperae-c-006-magnificat-pc0.krn
Jeśli zapis zawiera kolejne zmiany i poprawki innych skryptorów, dla
każdej warstwy należy przygotować osobne pliki, których nazwy należy
opatrzyć przyrostkami -pc1, -pc2 itd. UWAGA:
plik o przyrostku -pc1 powinien być oparty na pliku
-pc0 a nie na głównej wersji pliku, z kolei
-pc2 powinien się opierać na wersji -pc1.
W Aneksie (zob. 8) przedstawione zostały przykłady ilustrujące najczęściej spotykane w źródłach sytuacje. W przypadkach wątpliwych i trudnych do rozstrzygnięcia należy skontaktować się z koordynatorem projektu.
Pełne nazwy głosów w edycji dyplomatycznej powinny być wierną transkrypcją zapisu źródłowego. Jedynym odstępstwem od tej reguły jest rozwinięcie abrewiatur słownych. Jeśli wpisana w źródle nazwa głosu jest błędna, na przykład podaje błędną tonację instrumentu transponującego, to do pierwszego dźwięku tej partii dodać należy notatkę opisującą tę sytuację. Jeśli w źródle nie występuje nazwa partii, ale na podstawie kontekstu można ze stuprocentową pewnością wywnioskować, jaki instrument realizuje daną partię, właściwą nazwę należy zakodować w źródle w nawiasie kwadratowym.
W przypadku zapisu w głosach skrótowe nazwy instrumentów nie pojawiają się nigdy. Mimo to, dla ułatwienia nawigacji w edycji należy dodać także nazwę skrótową. Skrótowe nazwy powinny być zgodne z wytycznymi RISM, dostępnymi pod poniższym linkiem. W źródłach partyturowych, jeśli skrót nazwy został użyty, należy uwzględnić go zgodnie ze źródłem. Jeśli został pominięty, zastosować należy ujednolicone skróty zgodne z RISM.
Edytorzy plików krn są także zobowiązani do zakodowania ujednoliconego kodu instrumentu, klasy, do której należy, a także – w odpowiednich przypadkach – grupy instrumentów:
kod instrumentu powinien zostać umieszczony w
liniach następujących po źródłowych nazwach głosów, grup i skrótach nazw
głosów. Podajemy go w formie *Ikodinstrumentu, na przykład
*Ipiano, *Isoprn.
klasa instrumentu powinna zostać zakodowana pod
kodem instrumentu w formie *ICklasainstrumentu, na przykład
*ICvox, *ICbras.
grupa instrumentów powinna być zakodowana tylko
w przypadku gdy jest ona jasno zdefiniowana w źródle. Przykładem takich
sytuacji może być wydzielenie partii basso continuo, lub instrumentu
solo. Grupę instrumentów należy zakodować w forimie
*IGgrupainstrumentów, na przykład
*IGcont.
Pełna lista kodów instrumentów, klas i grup znajduje się pod poniższym linkiem.
Powinny być zawsze zapisane w oryginalnej postaci. Jeżeli partia zapisana jest w kluczu C1, zapisujemy ją właśnie w tym kluczu – nie zamieniamy kluczy na współczesne (np. zostawiamy klucz tenorowy nie zamieniając na wiolinowy z przenośnikiem oktawowym).
Wyjątkiem od tej zasady jest zmiana klucza na błędny, lub brak
koniecznej z punktu widzenia zmiany klucza w źródle. W takiej sytuacji w
transkrypcji do pliku krn należy wprowadzić właściwą/niezbędną zmianę
klucza, a następnie oznaczyć klucz jako redakcyjny za pomocą komentarza
lokalnego w formie !LO:CL:ed.
Wpisujemy jak oryginale, nawet jeśli są nieadekwatne.23
Transpozycja instrumentu musi być uwzględniona w edycji – kluczowe są
w tym przypadku brzmiące wysokości dźwięków, które muszą być poprawnie
zakodowane w formacie Humdrum. Transpozycję instrumentu należy oznaczyć
za pomocą interpretacji typu *ITrd[n]c[m] przy czym:
literę n należy w tym przypadku zastąpić numerem,
oznaczającym diatoniczną odległość zapisu nutowego od wysokości
brzmiących: 1 oznacza sekundę, 2 - tercję
itd.
literę m należy zastąpić liczbą półtonów dzielących
zapis nutowy od wysokości brzmiących: 1 oznacza sekundę
małą, 4 - to cztery półtony, czyli tercja wielka
itd.
W przypadku instrumentów transponujących w dół (gdzie zapis nutowy
jest wyższy od brzmiących wysokości dźwięków) taka forma zapisu
wystarczy, by poprawnie opisać transpozycję instrumentów. Dla przykładu
*ITrd1c2 to oznaczenie transpozycji o sekundę w dół, na
przykład dla Klarnetu in B. Kodowanie instrumentów transponujących w
górę (gdzie zapis nutowy jest niższy od rzeczywiście brzmiących
dźwięków) przed liczbami n i m należy dodać
-. Dla przykładu Corno in Es zakodować należy jako
*ITrd-2c-3.
Choć divisi i colla parte to zasadniczo dwie różne sytuacje, w formacie Humdrum należy je przetranskrybować w podobny sposób, analogicznie do tego, opisanego w części poświęconej transkrypcjom do formatu MusicXML (por. 3.1.3.4).
Należy wpisać zgodnie z zapisem oryginalnym. Jeśli brak metrum w źródle, należy oznaczyć to komentarzem tekstowym. Przykład 3.16 przedstawia kodowanie oznaczeń metrycznych typowych dla białej notacji menzuralnej i notacji pochodnych:
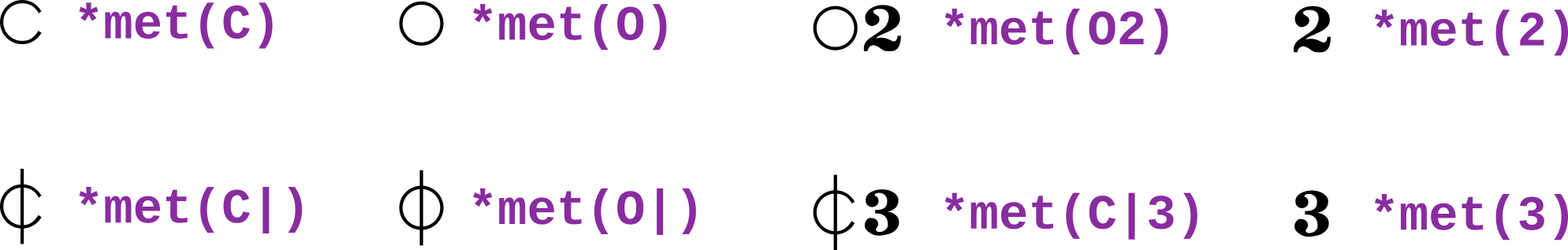
Pauzy, które wykraczają poza ramy taktu w transkrypcji należy przetranskrybować zgodnie ze źródłem, to jest odwzorować długość każdej z pauz składowych. Nie należy przy tym ukrywać kresek taktowych w trakcie trwania pauzy wielotaktowej.
Poniżej przykładowa pauza wielotaktowa i schemat jej kodowania w formacie Humdrum:

**kern
=
00r
=
.
=
.
=
.
=
0r
=
.
=
1r
==
*-Warto zwrócić uwagę, że wartości rytmiczne pauz wielotaktowych
oznaczają właściwą liczbę taktów w metrum, w którym miarę taktu wyznacza
cała nuta. W innym metrum, na przykład w metrum 3/4 kodowanie musi być
nieco inne – pauza podobna jak w powyższym przykładzie, również
obejmowałaby 7 taktów, jednak nie byłoby to zgodne z zakodowanymi
wartościami rytmicznymi (longa + brevis + cała nuta). W tym przypadku
pauzy wielotaktowe należałoby zakodować jako brevis z kropką + cała nuta
z kropką + półnuta z kropką, a wyświetlanie każdej z wartości
rytmicznych zmienić za pomocą komentarza lokalnego
LO:N:vis=. Właściwe kodowanie wyglądałoby więc tak:
**kern
=
!LO:N:vis=00
0.r
=
.
=
.
=
.
=
!LO:N:vis=0
1.r
=
.
=
!LO:N:vis=1
2.r
==
*-Klamry czyli akolady wpisujemy jak w źródle, o ile mamy do czynienia z zapisem partyturowym. Jeśli tworzymy skład z ksiąg głosowych, głosy układamy w odpowiedniej kolejności (por. Aneks, tabela 8.1), a grupy łączymy akoladą. W formacie Humdrum akolady mogą być kodowane na dwa sposoby:
za pomocą !!!system-decoration: (zob. przyk. 3.18)
za pomocą oznaczeń *group oraz
!!!system-decoration: (zob. przyk. 3.19)


Mimo, że obie formy kodowania są poprawne składniowo, należy — o ile to możliwe — stosować formę drugą. Pozwoli to w przyszłości na łatwiejsze stworzenie wyciągów głosowych z pełnej partytury.
Zapisujemy je dokładnie jak w źródle. W starszych źródłach bardzo
często występują tzw. znaki przypominające – należy je zawsze
skrupulatnie wypisać. W formacie Humdrum przypominające znaki
chromatyczne koduje się przez dodanie X po oznaczeniu
akcydencji: 4c#X. Nie dodajemy żadnych akcydencji nawet gdy
ich brak jest ewidentnym błędem. Zwłaszcza w starszych źródłach można
spotkać się z zapisywaniem kasownika za pomocą krzyżyka – w takiej
sytuacji należy zakodować kasownik poprawnie (4cn), a w
linii powyżej, bezpośrednio nad tokenem dodać !LO:N:acc=#.
Takie kodowanie pozwoli oddać zarówno intencję skryptora, jak i
graficzną formę zapisu.
Artykulacja powinna być wpisana jak w źródle. Pozycja znaku (nad lub
pod nutą) powinna być zachowana w transkrypcji. Nie należy
uwspółcześniać notacji oznaczeń. Dotyczy to w szczególności kreski
pionowej, która może oznaczać – w zależności od kontekstu –
détaché, tasto solo, lub staccatissimo.
Kreski tej nie należy zamieniać na (staccato) lub
(staccatissimo) – w zamian, do nuty, przy której w źródle
pojawia się takie oznaczenie, należy dodać | (wraz z
informacją, czy oznaczenie zostało wpisane nad, czy pod nutą), a
następnie, na końcu pliku dodać linię
!!!rdf**kern: | = vertical stroke.
Jeśli w pliku źródłowym, przekonwertowanym z formatu MusicXML pionowe
kreseczki zapisane są w formie notatki tekstowej
(!LO:TX:t=|), należy zmienić ich kodowanie na opisane
powyżej. Można to zrobić także przy użyciu skryptu
strokes.py, zamieszczonego w Aneksie (por. 8.2).
Powinny być wpisane jak w źródle. W szczególności dotyczy to oznaczenia t, które w starszych rękopisach może oznaczać trillo i nie należy go zamieniać na tr.
Należy wpisać jak w źródle nawet, jeśli oznaczałoby to zapis
niepoprawny. Należy zachować wartości rytmiczne przednutek jak w źródle
oraz zachować rozróżnienie pomiędzy acciacatura
(8qc) i appoggiatura (8qqc) używając
przekreślenia lub nie.
W formacie Humdrum możliwe jest poprawne zakodowanie obu rodzajów
flażoletów - naturalnych i sztucznych. Flażolety naturalne koduje się
przez dodanie znacznika artykulacyjnego o do nuty. Efektem
tego kodowania jest dodane małe kółko nad główką nuty.
Z flażoletami sztucznymi sprawa jest nieco bardziej skomplikowana.
Notacja takich dźwięków może składać się z trzech lub dwóch dźwięków, z
których część nie stanowi dźwięków rzeczywiście brzmiących – wskazują
jedynie sposób wydobycia dźwięku. Dźwięki niebrzmiące należy w związku z
tym zakodować jako pauzy na odpowiedniej wysokości. Pauza w akordzie
będzie wyświetlona jako dźwięk, ale nie będzie brana pod uwagę w
analizie muzycznej. Dźwiękiem niebrzmiącym jest zazwyczaj najniższy
dźwięk w notacji flażoletu, który wskazuje w którym miejscu należy
skrócić strunę. Drugi z niebrzmiących dźwięków wskazuje, gdzie należy
stłumić strunę, żeby wydobyć właściwy dźwięk - przeważnie jego główka ma
kształt rombu. Aby osiągnąć ten efekt w edycji w formacie Hudmdrum i w
graficznej partyturze, należy zmienić wyświetlanie główki za pomocą
komentarza lokalnego !LO:N:n=2:notehead=rhombus. Jeśli
sytuacja tego wymaga, to, czy główka nuty będzie wypełniona czy nie
zmienić można, dodając do powyższego komentarza parametr
vis=2. Jeśli któryś z dźwięków flażoletu został pominięty w
notacji, należy go zakodować jako dźwięk ukryty24.
Trzy możliwe sytuacje w kodowaniu flażoletów, przedstawione w przykładzie, umieszczonym w sekcji poświęconej edycjom w formacie xml (por. 3.6), należy zakodować następująco:
**kern
*clefG2
=1
!LO:N:n=2:vis=2:notehead=rhombus
4ccc 4fr 4cr
!LO:N:n=2:vis=2:notehead=rhombus
4cccyy\ 4fr 4cr
!LO:N:n=2:vis=2:notehead=rhombus
4ccc 4fr 4cryy
==
*-Jeśli na końcu linii w źródle pojawia się kustosz (łac.
custos), w transkrypcji dyplomatycznej po nucie, po której
występuje, należy dodać interpretację
*custos:[wysokość dźwięku], na przyklad
*custos:G.
Format Humdrum umożliwia kodowanie znaków białej notacji menzuralnej
przy pomocy formy zapisu **mens, jednak nie należy jej
stosować w transkrypcjach dyplomatycznych. Kompozycje zapisane białą
notacją menzuralną czy też jej późniejszymi odmianami i wariantami
należy zawsze transkrybować jako **kern, czyli odpowiednik
współczesnej notacji muzycznej. Inaczej rzecz się ma w przypadku muzyki
zapisanej za pomocą notacji neumatycznych (nota quadrata,
notacja metzeńska lub inne) – w takich przypadkach należy stosować zapis
dwuspinowy:
w spinie **kern należy umieścić wysokości dźwięków
bez wartości rytmicznych (np. c). Dźwięk rozpoczynający
neumę wielodźwiękową, należy poprzedzić nawiasem otwierającym
((c), po dźwięku kończącym neumę należy dodać nawias
zamykający (c)).
w spinie **neume należy wprowadzić łacińską nazwę
neumy (np. punctum, virga, pes,
clivis…).
Wiele źródeł polifonicznej muzyki szesnasto- i siedemnastowiecznej zawiera fragmenty chorałowe. Przeważnie są one zapisane notacją przypominającą znaki zakolorowanej notacji menzuralnej. Tego typu wstawki należy traktować jak białą notację menzuralną.
Łuki frazowe i artykulacyjne w formacie Humdrum można przypisać wyłącznie do nut i pauz – nie ma możliwości zakodowania łuku, rozpoczynającego lub kończącego się na kresce taktowej, między nutami itp.
W sytuacji gdy łuki się krzyżują (zob. przyk. 3.20) konieczne
jest oznaczenie początku i końca jednego z łuków znakiem
& umieszczonym przed nawiasem jak w poniższym
przykładzie:

**kern
&(4c
(4d
4e&)
4f)
*-Jeśli krzyżowanie dotyczy trzech i więcej łuków, początek i koniec
każdego kolejno łuku muszą zostać oznaczone znacznikami
&&, &&& itd. Należy
zakodować wertykalną pozycję łuku (nad lub pod nutami). Dotyczy to
zarówno łuków, frazowych czy artykulacyjnych, jak i ligaturowych. Łuki
łączące nuty w partiach wokalnych, za pomocą których oznaczono
melizmaty, należy wpisać zgodnie z zapisem źródłowym.
W transkrypcji dyplomatycznej w formacie Humdrum kreski taktowe powinny być zakodowane najwierniej jak to możliwe w stosunku do źródła. Sytuacje, których nie da się zakodować – niekompletne kreski taktowe, brak kresek taktowych na niektórych pięcioliniach, kreski taktowe w różnych miejscach w różnych głosach – należy dostosować do aktualnego metrum i opatrzyć notatką tekstową, opisującą stan źródłowy.
Format Humdrum nie wymusza stosowania kresek taktowych, jednak kompozycje oryginalnie zapisane bez kresek i podziałów powinny być ujęte w takty równej długości zgodnie z oznaczeniem metrycznym. Za miarę taktu należy przyjąć wartość jednej brevis, (dwudzielnej lub trójdzielnej w zależności od oznaczenia menzuralnego). Wartości rytmiczne, zarówno nut jak i pauz, dłuższe niż miara taktu powinny być zapisywane w formie identycznej ze źródłową – nie należy dzielić długich wartości na krótsze, połączone łukiem ligaturowym (właściwy zapis po lewej):
[tabsize=18]
**kern **kern
M2/1} M2/1
*met(C|) *met(C|1)
=- =-
0.c [0c
= =
. 1c]
1c 1c
== ==
*- *-Powinny zostać rozpisane. Dźwięki zapisane jedną abrewiacją powinny
być połączone belką. Bezpośrednio przed pierwszym dźwiękiem
tremolo należy dodać interpretację *tremolo, a
bezpośrednio po ostatniej nucie – *Xtremolo.
W transkrypcji dyplomatycznej Humdrum należy zakodować w spinie
**text. Kolejne zwrotki tekstu słownego powinny być
dodawane w kolejnych spinach, przy czym każdy powinien być oznaczony na
początku za pomocą intepretacji
*v:[n],
gdzie n należy zastąpić kolejnymi numerami zwrotek25. Tekst należy wpisać w pisowni
oryginalnej, zachowując także wszelkie błędy pisowni oraz cechy
specyficzne, w tym znaki diakrytyczne.
Ewidentne omyłki skryptora należy oznaczyć notatką typu
SIC, umieszczoną w spinie **text nad
odpowiednią sylabą tekstu słownego, co ilustruje poniższy przykład:
**kern **text
4c sy-
4c -la-
! !LO:SIC:v:s=-ba
4c -bq
4c zła
*- *-Czasem w zapisie kompozycji pojawiają się kreseczki, umieszczone między nutami, lub na dole pięciolinii, które wskazują, gdzie kończą się słowa tekstu słownego i jak należy je podłożyć pod nutami.
W toku projektu przyjęto, że tego typu kreski w transkrypcji w
formacie Humdrum należy przetranskrybować jako oddechy (,),
umieszczone pod nutą. Przykład, zaprezentowany w części, poświęconym
transkrypcjom do formatu MusicXML (por. 3.8)
należy więc przetranskrybować następująco:
**kern **text
*k[b-] *
*F: *
=40- =40-
1C,< -num
2D/ et
1D\ in
=41- =41-
2C#X/ ae-
2D/ -ter-
2AA/ .
=42- =42-
*lig *
1BB- .
1AA .
*Xlig *
=43- =43-
1D,< -num
*lig *
1F per-
=44- =44-
1G .
*Xlig *
2A\ .
2AA/ .
=45- =45-
2.BB-/ -ma-
4AA/ .
2GG,</ -nes
* *ij
[<2Cny/ per-
=46- =46-
4C] .
4BB-/ -ma-
2AA,</ -nes
* *Xij
2.D\ per-
4C/ -ma-
=47- =47-
1BB-,< -nes
1C Vir-
=48- =48-
2FF,</ -go
2F\ et
2F\ in
2E\ ae-
=49- =49-
2F\ -ter-
2C/ .
== ==
*- *-
!!!RDF**kern: < = below
!!!RDF**kern: > = aboveSzczegółowy opis zasad transkrypcji tekstu słownego w rozdziale 6.
W wielu źródłach powtórki tekstu słownego oznaczane są skrótowo za
pomocą oznaczenia repetycji26. Powtórzone słowa lub
fragmenty tekstu słownego podpisać pod nutami tak samo jak tekst
wzorcowy, a jeśli to nie możliwe, zgodnie z zasadami podkładania tekstów
słownych. Przed pierwszą sylabą powtórzonego fragmentu tekstu, w spinie
**text należy dodać interpretację *ij, a po
ostatniej sylabie – *Xij.
W części poświęconej plikom xml opisano przypadek podłożenia różnych
zwrotek w różnych głosach. W edycjach w formacie Humdrum należy tę
kwestię rozwiązać inaczej niż w przypadku plików xml. W przykładzie 6.1 pod najwyższym głosem umieszczono
pierwszą zwrotkę, pod głosem środkowym, zwrotkę drugą a pod najniższym
zwrotki 3–7. W edycji w formacie Humdrum wszystkie głosy powinny mieć
taką samą liczbę spinów tekstowych, przy czym w spinie najwyższego głosu
spiny tekstowe od *v:2 do *v:7 pozostaną
puste, w głosie środkowym tekst będzie umieszczony tylko w spinie
*v:2 itp.
W formacie Humdrum należy dodawać w spinie **dynam.
Dotyczy to zarówno oznaczeń skrótowych (f, mp,
sf), graficznych, jak i słownych (cresc,
diminuendo). W przypadku oznaczeń skrótowych kodowanie jest
oczywiste – f = f, sfz =
sfz. Do kodowania oznaczeń graficznych stosuje się znaki
< początek crescendo, > początek
diminuendo, [ koniec crescendo i ] koniec
diminuendo. Oznaczenia słowne koduje się na dwa sposoby, w zależności od
sytuacji źródłowej:
dla oznaczeń, które nie mają określonego czasu trwania stosuje
się niezamknięty początek symbolu graficznego (< lub
>). Domyślnie < oznacza cresc.,
a > – decresc., możliwe jest jednak zakodowanie
innego znaczenia tych symboli. Jeśli w całej kompozycji zamiast
decres. pojawia się dim, na końcu kodu Humdrum27 należy dodać linię
!!!RDF**dynam: > = dim. Jeśli tego typu oznaczenia nie
mają spójnej formy, dla każdego kodowania w spinie **dynam
można przypisać tekst. W tym celu nad odpowiednim oznaczeniem w spinie
**dynam należy dodać linię
!LO:HP:t=[tekst oznaczenia].
dla oznaczeń słownych, które w źródle mają precyzyjnie
zdefiniowane zakończenie kodowanie wygląda nieco inaczej. W pierwszej
kolejności należy zakodować zamknięte crescendo lub
diminuendo w spinie **dynam. Następnie
bezpośrednio nad oznaczeniem należy dodać linię
!LO:HP:t=[tekst oznaczenia dynamicznego].
Jeżeli w źródle w zapisie słownego oznaczenia dynamicznego pojawiają się
linie wypełniające, powyższą linię należy uzupełnić o
:ext=[ext code]:ext=[ext code].
Parametr ext w linii odnosi się do formy linii
rozdzielającej słowa, ext2 z kolei dotyczy linii między
sylabami. Wartości ext code i ich znaczenia prezentuje
tabela 3.2:
| ext code | znaczenie |
|---|---|
u |
ciągła linia na wysokości linii bazowej tekstu |
c |
ciągła linia w połowie wysokości tekstu |
ud |
przerywana linia na wysokości linii bazowej tekstu |
cd |
przerywana linia w połowie wysokości tekstu |
ut |
kropkowana linia na wysokości linii bazowej tekstu |
ct |
kropkowana linia w połowie wysokości tekstu |
s |
spacja (brak linii) |
Nie należy dodawać ani ujednolicać oznaczeń. Należy zachować
położenie oznaczenia w układzie wertykalnym. Jeśli sytuacja źródłowa
jednoznacznie wskazuje, że oznaczenie dynamiczne znajduje się między
dźwiękami, można je przypisać do pustego tokenu .. W
przeciwnym razie oznaczenia dynamiczne powinny być przypisane do
odpowiednich dźwięków.28
Repetycje obejmujące wszystkie głosy partytury powinny zostać
oznaczone jak w źródle i nie należy ich rozpisywać. Każdy odcinek, który
jest powtarzany, należy oznaczyć w każdym spinie **kern za
pomocą znacznika
*>[KOLEJNA LITERA ALFABETU],
na przykład *>A. Pierwszą, drugą i kolejne wolty należy
oznaczyć taką samą literą co powtarzany fragment, rozbudowaną kolejnymi
numerami (np. *>A1, *>A2).
Znaki powtórek oraz oznaczenia (zarówno słowne, jak i symbole, np.
dal segno al Fine etc) należy dodać jako notatka tekstowa
(!LO:TX:a:i:t=dal segno al Fine). Znaki graficzne
segno () oraz coda () można zakodować jako odpowiednio
!LO:TX:t=[segno]
i
!LO:TX:t=[coda].
Dodatkowo dla każdej kompozycji zawierającej repetycje należy
określić formę, dodając po linii **kern a przed pierwszym
taktem interpretację
*>[A,B,..]
– w nawiasie kwadratowym powinny się znaleźć liczbowo-literowe
oznaczenia części utworu. Przykład 3.21 prezentuje
zapis z repetycjami oraz jego odpowiednik w formacie Humdrum:

**kern
*>[A,A1,A,A2,B,C,B]
=-
*>A
1c
=:|
*>A1
1d
=
*>A2
1e
=
*>B
1f
!LO:TX:a:t=Fine
.
=
*>C
!LO:TX:t=Dal [segno] al Fine
1g
==
*-Jeśli repetycja pojawia się tylko w niektórych głosach kompozycji, to
powtórzony fragment musi być zakodowany identycznie jak fragment
źródłowy, przy czym wszystkie elementy powinny zostać ukryte za pomocą
znaczników yy. Przy pierwszym dźwięku należy dodać notatkę
LO:TX:t=P:problem=t. x-y zapisane repetycją.

**kern **dynam
*group1 *
*part8 *part8
*staff8 *
*I"Fagoto 2do *
*I'fag 2 *
*Ifagot *
*ICww *
*clefF4 *
*C: *
*M2/4 *
*2\right *
=100 =100
2A\ p
4G\ .
=101 =101
4F#X\ .
4G\ .
4r .
=102 =102
!LO:TX:t=P:problem=t. 102-103 zapisane repetycją !
2A\yy py
4G\yy .
=103 =103
4F#X\yy .
4G\yy .
4ryy .
== ==
*- *-Repetycje zanotowane znakiem powtórzenia na pięciolinii, obejmujące
jeden takt, lub mniej (np. grupę ósemkową), należy powtórzyć dosłownie,
a następnie przed pierwszym dźwiękiem dodać oznaczenie
*rep, a po ostatnim dźwięku *Xrep, jak
poniższym przykładzie:

**kern
*group1
*part8
*staff8
*I"Fagoto 2do
*mI"Fagoto II
*I'fag 2
*Ifagot
*ICww
*clefF4
*k[]
*C:
*M4/4
*met(c|)
*2\right
=171
4C\
4c\
4C\
4c\
=172
*rep
4C\
4c\
4C\
4c\
*Xrep
=173
*rep
4C\
4c\
4C\
4c\
*Xrep
=174
*rep
4C\
4c\
4C\
4c\
*Xrep
*-Łamania systemów i stron w transkrypcjach dyplomatycznych w formacie
Humdrum koduje się odpowiednio za pomocą komentarzy
!LO:LB:g=original i !LO:PB:g=original. Jeśli
zapis źródłowy to partytura kodowanie łamań systemów i stron powinno być
zakodowane jako komentarz globalny,29 np.
!!LO:LB:g=original. Jeśli kompozycja została zapisana jako
osobne głosy, informację o łamaniach należy dodać jako komentarz lokalny
dla każdego głosu osobno.
Belkowanie (ang. beaming) nut należy wpisać jak w źródle nawet, jeśli jest ono niezgodne z zapisanym metrum i współczesnymi zasadami ortografii muzycznej. Nie należy uzgadniać belkowania w partiach wokalnych z sylabami tekstu słownego, tylko pozostawić jak w źródle.
Jeśli pozycja belki w stosunku do nut nią objętych się zmienia, przy
każdej nucie należy zakodować kierunek ogonka zgodnie z sytuacją
źródłową. Dodatkowo, przy pierwszym dźwieku belki należy dodać notatkę
!LO:TX:t=P:problem=mixed beam.
Przykład umieszczony w sekcji poświęconej belkowaniu w plikach XML (por. 3.10) należy zakodować w następujący sposób:
**kern
!LO:TX:t=P:problem=mixed beam
8C 8CCL/
8e 8c 8G\
8e 8c 8G\J
*-W źródłach – zarówno drukowanych, jak i rękopiśmiennych – zdarza się,
że cyfry i klamry oznaczające grupy niemiarowe obejmują niestandardową
liczbę dźwięków. W formacie Humdrum istnieje możliwość określenia
wartości rytmicznej, która powinna być objęta klamrą. Używa się do tego
celu komentarza lokalnego !LO:TUP:r=[n], gdzie
[n] to wartość rytmiczna, jaką ma obejmować klamra30.
W przykładzie pierwszym będzie to półnuta, czyli r=2
(por. 3.24):

**kern
*clefF4
*k[b-e-]
=
[2a
!LO:TUP:a:r=2:xbr
(12aL']
12g'
12f#J'
12e-XL'
12d'
12cJ')
*-W przykładzie drugim natomiast dwa razy ósemka, czyli
r=8 (por. 3.25):

**kern
!LO:TUP:a:r=8
(24ggLL
24ff
24ggJ)
!LO:TUP:a:r=8
(24aaL
24gg
24ffJJ)
8eeL
8ddJ
*-
imageOznaczenia bc należy zakodować w spinie **fba.31
Kodowanie powinno jak najwierniej oddawać sytuację źródłową. Jeśli
figura składa się z dwóch lub więcej cyfr, cyfry należy zakodować od
góry, to jest od największej do najmniejszej, oddzielając znaki
spacjami. Akcydencje koduje się podobnie jak w spinie
**kern (# = krzyżyk, - = bemol
n = kasownik), przy czym zgodnie z współcześnie przyjętą
konwencją edytorską, akcydencję należy zakodować przed cyfrą. Jeżeli w
źródle znak akcydencyjny znajduje się po cyfrze, do kodowania należy
dodać r (np. n6r). Jeśli taka konwencja zapisu
występuje w całym źródle, zamiast dodawać r do każdej
figury można skorzystać z pary interpretacji
*reverse/*Xreverse. Interpretacja
*reverse informuje, że znaki chromatyczne w źródle
umieszczone są po cyfrze do końca utworu, lub do interpretacji
*Xreverse.
Jeśli w czasie trwania jednego dźwięku cyfrowanie się zmienia,
kolejne figury należy zakodować przy pustych tokenach w spinie
**kern.
Do kodowania linii wypełniających używa się znacznika :.
Znacznik wstawiony po cyfrze kodowania (przed spacją rozdzielającą cyfry
lub na końcu tokenu) oznacza linię wypełniającą, poprowadzoną do
następnego znaku na tym samym poziomie. : między cyframi
(np. 4:3) oznacza linię łączącą zmieniające się cyfry.
Nierzadko dla zachowania logiki prowadzenia głosów w cyfrowaniu
stosuje się tzw. wypełniacze – x lub X:
[tabspace=18]
**kern **fba
4c 6 4
4d x 3
*- *-Różnica między wielką i małą literą polega na tym, że X
kończy linie wypełniające zakodowane w poprzedniej figurze, a
x nie.
W siedemnasto- i osiemnastowiecznych zapisach cyfrowania częstą sytuacją jest stosowanie krzyżyka lub bemola w funkcji kasownika. Islutruje to przykład 3.26.

Format Humdrum umożliwia w takich sytuacjach kodowanie zarówno
informacji graficznej, jak i semantycznej. W pierwszej kolejności należy
zakodować znak, który faktycznie został użyty, a następnie jego
znacznie. Dla powyższego przykładu kodowanie cyfrowania wyglądałoby
następująco: #n.
Format Humdrum pozwala na kodowanie skrótowych zapisów akcydencji
przy cyfrowaniu w formie przekreśleń. Odwrotnie niż przypadku krzyżyków
użytych w formie kasownika, w pierwszej kolejności należy poprawnie
zakodować znaczenie muzyczne znaku (np. n6), a następnie
dodać oznaczenie przekreślenia – / dla kreski ukośnej z
dołu do góry, \ dla kreski ukośnej z góry na dół, dla
kreski pionowej (np. n6\).
Szczegółowe informacje na temat kodowania basso continuo znaleźć można w dokumentacji Verovio Humdrum Viewer.32
Komentarz tekstowy w formacie Humdrum dodaje się przy użyciu komentarzy lokalnych, umieszczonych bezpośrednio nad dźwiękiem, którego komentarz dotyczy. Jeśli komentarz dotyczy dłuższego fragmentu, należy go go dodać przed pierwszym dźwiękiem. Komentarze tekstowe powinny być zakodowane następująco:
!LO:TX:a:t=P:problem:[zwięzły opis problemu]
Jeśli komentarz odnosi się do treści zakodowanych jako komentarze lokalne, może być dołączony do takiego komentarza, np.:
!LO:TX:a:i:t=Poco a poco crescendo:problem:zapis czerwonym atramentem.
Poniżej przedstawiono (niepełną) listę problemów, jakie najczęściej można spotkać podczas tworzenia transkrypcji.
Wysokości dźwięków powinny być zakodowane tak jak w źródle, nawet
jeśli są one wpisane ewidentnie błędnie. Ewidentne błędy należy oznaczyć
notatką typu SIC, analogicznie zgodnie z opisem w części
poświęconej plikom MusicXML o takim samym tytule. Przykład, ilustrujący
właściwy zapis błędnego dźwięku w partii Alto w formacie Humdrum
powinien być zakodowany następująco:
**kern **text **dynam
*part2 *part2 *part2
*staff2 *staff2 *
*Ialto * *
*I"ALTO. * *
*I'A * *
*clefC3 * *
* * *
*k[f#] * *
*e: * *
*M2/2 * *
*met(c|) * *
=56 =56 =56
1e\^ lu- .
=57 =57 =57
!LO:SIC:s=2.f ! !
2.f#\ -men .
4r . .
== == ==
*- *- *-
!!!system-decoration: [(s1,s2,s3,s4,s5)]
!!!RDF**kern: > = above
!!!RDF**kern: < = below
Często w wyniku pomyłki skryptora, litografa lub zecera w źródle
wpisane są złe wartości rytmiczne, przez co długość taktu jest niepełna
lub przepełniona w stosunku do metrum lub oznaczenia metrycznego. W
takich przypadkach w formacie Humdrum zawsze należy zakodować wartość
właściwą, to jest zgodną ze miarą taktu. Informacja o rzeczywistym
stanie źródłowym powinna zostać zakodowana bezpośrednio nad dźwiękiem w
formie komentarza lokalnego
!LO:N:vis=[wartość].
Oznaczenie
[wartość]
każdorazowo powinno być zastąpione cyfrowym oznaczeniem wartości
rytmicznej w źródle (4 dla ćwierćnuty, 8. dla
ósemki z kropką itp.). Przykład 3.27
ilustruje możliwe błędy w źródle.

Transkrypcja tego zapisu powinna wyglądać jak w poniższym przykładzie:
**kern **kern
*M4/4 *M4/4
!LO:N:vis=1 !
2c 2ee
! !LO:N:vis=4
2c 2ee
= =
! !LO:N:vis=2
2c 8eeL
. 8ee
. 8ee
. 8eeJ
!LO:N:vis=4 !
2r 2r
== ==
*- *-Niejednoznaczność zapisu to jeden z najczęściej spotykanych problemów. Zwykle dotyczy wysokości nut (nie jest jasne, czy nuta jest w polu czy na linii), oznaczeń artykulacyjnych, dynamicznych, rozmieszczenia łuków etc. Najczęściej problem ten jest stosunkowo łatwy do rozwiązania, bowiem logika przebiegu muzycznego podpowiada właściwy wybór. Jeśli jednak nie można jednoznacznie stwierdzić, jakie rozwiązanie jest właściwe, należy przyjać jedną z możliwych opcji i dodać lokalny komentarz tekstowy.
W zapisie głosowym (głosy instrumentalne, księgi głosowe lub chórowe)
nierzadko zdarza się, że pominięto fragment kompozycji. Taki fragment —
niezależnie od jego długości — należy zakodować jako ukryte pauzy (np.
1ryy). Nad pierwszą pauzą należy dodać komentarz lokalny
LO:TX:a:t=P:problem=pominięty fragment.
Rzadszą, choć nie niespotykaną sytuacją, zwłaszcza w rękopisach, jest
omyłkowe powórzenie fragmentu kompozycji w jednym z głosów. W takich
przypadkach nadmiarowy fragment należy odpowiednio zakodować, a partie
pozostałych głosów uzupełnić ukrytymi pauzami. Nad pierwszym dźwiękiem
niepotrzebnie dodanego fragmentu należy umieścić komentarz lokalny
LO:TX:a:t=P:problem=niepotrzebnie powtórzony fragment.
Analogicznie do instrukcji w części poświęconej plikom xml (por. 3.1.4.5), fragmenty pominięte i dopisane
przez tego samego kopistę należy w transkrypcji wpisać w miejscu, na
które wskazuje przebieg muzyczny. Początek i pominiętego fragmentu
należy opatrzyć notatką, opisującą sytuację źródłową, np.
!LO:TX:a:t=P:problem=t. 102-104 wpisane na dole strony.
Wszystkie źródłowe oznaczenia, wyjaśniające sposób wykonania utworu (np.
Vi=, =de, re=, =tro) również muszą
się znaleźć w transkrypcji.
Jeśli dodany fragment to późniejsza ingerencja w źródło i jeśli
zmienia on poprawny zapis, na przykład przez dodanie muzyki w miejsce
odcinka pauz, należy kierować się zasadami, określonymi w podrozdziale
Lekcja (por. 3.2.1) -
pierwotny wariant zostanie umieszczony w pliku -pc0, a
dodany fragment wpisać należy do pliku -pc133.
Edycje dyplomatyczne w formacie Humdrum, odwzorowujące źródło muzyczne w możliwie najwierniejszy sposób nie zawsze mogą być zastosowane do potrzeb wykonawczych. Dlatego też dla wybranych kompozycji zostanie przygotowana także edycja uwspółcześniona. Ten typ edycji stanowi etap pośredni między wersją dyplomatyczną i krytyczną – wciąż opiera się na jednym tylko źródle, ale prezentuje treść muzyczną w formie nowoczesnej, ujednoliconej i dostosowanej do potrzeb wykonawczych, ale też do analizy muzycznej.
Dzięki niedawnym zmianom w formacie Humdrum, możliwe stało się kodowanie dwóch wariantów tej samej edycji w jednym pliku. Z założenia możliwe musi być łatwe i w pełni odwracalne przechodzenie między kodowaniem dyplomatycznym i uwspółcześnionym. Wzbogacenie edycji dyplomatycznej o wersję uwspółcześnioną polegać więc będzie na zakodowaniu wszystkich zmian i różnic występujących między wersjami, oraz na aktywowaniu odpowiedniego zestawu filtrów.
Dwa podstawowe filtry, które zawierać musi każdy plik, posiadający wersję uwspółcześnioną to:
sic -sq - zmienia błędne dźwięki, oznaczone etykietą
SIC na właściwe, zakodowane w parametrze s w
komentarzu lokalnym (!LO:SIC:v:s=[właściwy dźwięk], por. 3.1.4.1)
modori -m - ukrywa elementy zapisu dyplomatycznego,
a na ich miejsce wstawia elementy zakodowane jako współczesne.
W związku z tym na początku pracy nad plikiem należy na końcu dodać linię
!!!fiter: sic -sq | modori -mDo linii filtrów po znaczniku dodawać można kolejne filtry, w
zależności od potrzeb. Zastosowanie filtrów wyjściowych
(modori i sic) jest w pełni odwracalne (filtry
modori -o oraz sic -ov przywracają kodowanie
dyplomatyczne). Inaczej wygląda kwestia pozostałych filtrów - nie
wszystkie da się łatwo automatycznie przywrócić, dlatego nie
należy kompilować żadnych filtrów jeśli filtr uwspółcześniający jest
aktywny.
WAŻNE!
Po zakończeniu pracy nad plikiem należy zmienić
!!!filter: na !!!filter-modern:. Wszystkie
filtry zapisane w tym polu zostaną dezaktywowane, a Verovio Humdrum
Viewer wyświetli wersję dyplomatyczną edycji.
Aby aktywować ponownie filtry zapisane w polu
!!!filter-modern, należy użyć filtra
filter -v modern.
W edycjach dyplomatycznych nazwy głosów (instrumentów) podane są w brzmieniu źródłowym. W wersjach uwspółcześnionych nazwy te powinny zostać ujednolicone.
Uwspółcześnione nazwy instrumentów kodujemy w polu *mI".
Zastosowanie filtra modori -m sprawi, że nazwy źródłowe
zostaną przeniesione z pola *I" do *oI", a
nazwy uwspółcześnione trafią z *mI" do *I" i
zostaną wyświetlone w partyturze34.
Za współczesne, ujednolicone nazwy uważać będziemy nazwy włoskie,
pisane wielką literą. W przypadku instrumentów transponujących w nazwie
głosu powinien się też znaleźć strój instrumentu po przyimku
in. Bemol w dookreśleniu stroju instrumentu kodujemy jako
b, krzyżyk jako # (na przykład Corno in
Eb). Jeśli w kompozycji występuje więcej instrumentów tego samego
rodzaju, do nazwy należy dodać rzymski numer (np. Violino I,
Violino II).
Listę włoskich nazw najpopularniejszych instrumentów można znaleźć pod tym linkiem
W edycjach dyplomatycznych skrótowe nazwy powinny być zakodowane w
brzmieniu zgodnym z
wytycznymi RISM, chyba, że w źródle zapisano inny skrót.
Skróty instrumentów w edycjach uwspółcześnionych powinny mieć formę
zgodną z wytycznymi RISM bez względu na sytuację w źródle. Jeśli
źródłowy skrót nie jest tożsamy ze skrótem RISM, uwspółcześnioną nazwę
należy zakodować w polu *mI. Filtr modori -m
przeniesie skrót źródłowy z pola *I do *oI, a
wariant uwspółcześniony z pola *mI do *I.
W uwspółcześnionej wersji w miarę możliwości należy używać tylko
współcześnie występujących kluczy (G2, F4).
Współczesny kształt kluczy należy zakodować jako
*mclefG2/*mclefGv2/mclefF4 pod
linią kodowania kluczy. Filtr modori -m zmienia
dotychczasowe kodowanie dawnych kluczy z *clef na
*oclef a kodowanie kluczy współczesnych z
*mclef na *clef35.
Jeśli oznaczenia tonacji
(*k[])
w źródle nie są spójne, lub jeśli nie odpowiadają rzeczywistej tonacji
utworu, należy w partii zakodować właściwą tonację używając oznaczenia
*mk[].
Filtr modori -m zmieni kodowanie tonacji w źródle z
*k[] na
*ok[],
a kodowanie uwspółcześnione z
*mk[]
na
*k[]36.
Jeśli symboliczne oznaczenie metrum jest niespójne między głosami,
lub jeśli symboliczne oznaczenia pochodzą z białej notacji menzuralnej,
uwspółcześnione oznaczenia symboliczne należy zakodować, używając
oznaczenia *mmet(). Filtr modori -m zmieni
źródłowe kodowanie z *met() na *omet(), a
kodowanie uwsółcześnione z *mmet() na
*met().
W edycjach dyplomatycznych wartości w polu !!!OMD
dodawane są tylko, jeśli źródło jest partyturą i posiada jedno
oznaczenie dla wszystkich głosów. Jeśli źródło to głosy, oznaczenia
dotyczące części są kodowane w każdym głosie jako notatka tekstowa, w
brzmieniu źródłowym.
Aby uwspółcześnić notację oznaczeń części/tempa, należy:
Dodać puste oznaczenie !!!OMD:
Dodać oznaczenie !!!OMD-mod: przechowujące
uwspółcześnioną wersję oznaczenia części/tempa
Do każdej notatki będącej odpisem źródłowym oznaczenia
części/tempa w głosach należy dodać parametr :mod= (na
przykład !LO:TX:a:t=All.o:mod=)
Filtr modori -m zmieni źródłowe (puste) kodowanie
!!!OMD w !!!OMD-ori, a uwspółcześnione
!!!OMD-mod w !!!OMD. Z kolei wartość z
parametru t= w notatce tekstowej zostanie przeniesiona do
parametru ori=, a wartość wsółczesna (pusta) zakodowana w
parametrze mod= zostanie przeniesiona do parametru
t=37.
Analogicznie jak przypadku oznaczeń części, w edycjach dyplomatycznych adnotacje zanotowane w źródle w każdym głosie, a odnoszące się do całej partytury (np. Tutti) zakodowane są w każdym spinie w brzmieniu źródłowym. W edycjach tego typu notatki należy ukryć, a w ich miejsce dodać komentarz globalny.
Wstawienie komentarza globalnego najłatwiej zakodować następująco:
!!LO:TX:t= :mod=TuttiW zapisie szesnasto- i siedemnastowiecznej muzyki wokalnej nie
stosowano przeważnie kresek taktowych, dlatego w edycjach kreski taktowe
są ukryte. Wyświetlenie ukrytych kresek w wariancie uwspółcześnionym
edycji jest mozliwe dzięki filtrowi shed. Aby wyświetlić
ukryte kreski taktowe, należy do linii filtrów dodać
shed -e "s/-//B".
Nierzadko w zapisie głosowym łamania linii wypadają w środku taktu. W edycjach dyplomatycznych w miejscach łamania linii znajduje się często nienumerowana ukryta kreska taktowa. W wariancie uwspółcześnionym takie kreski powinny zostać ukryte za pomocą funkcjonalności pomijania całych linii kodu opisanej niżej (por. 4.3.2)
Jeśli w źródle zapisana jest niewłaściwa wysokość dźwięku, właściwą
wysokość (wraz ze wszystkimi atrybutami, takimi jak wartość rytmiczna,
belkowanie, artykulacje itp) należy zakodować w polu
!LO:SIC:s=[właściwy dźwięk]:v.
Po zastosowaniu filtra sic -sq kodowanie zostanie
zmienione na poprawne, a wartość źródłowa zostanie przeniesiona do
parametru o=.
Jeśli w źródle wartości rytmiczne są zapisane błędnie, w edycjach
dyplomatycznych stosuje się komentarz lokalny !LO:N:vis=,
dzięki któremu poprawnie zakodowana wartość rytmiczna wyświetla się
błędnie, jak w źródle. W edycjach uwspółcześnionych powinna się
wyświetlać wartość poprawna. Żeby w wariancie uwspółcześnionym
przywrócić poprawne wyświetlanie wartości rytmicznej należy skorzystać z
możliwości zmiany/usunięcia/dodania komentarza, opisanego niżej (por. 4.3.1.2).
Zdarza się też, że w źródle wartości rytmiczne na dłuższych odcinkach
są o połowę za krótkie lub dwa razy za długie. W edycjach
dyplomatycznych taką sytuację oddaje się za pomocą interpretacji
*rscale:n. W edycji uwspółcześnionej przeważnie tego typu
zapisy należy zmienić, by wyświetlały się właściwe wartości rytmiczne.
Aby to zrobić należy skorzystać z opcji zmiany/usunięcia/dodania
interpretacji, opisanej niżej (por. 4.3.1.1).
W przypadku, gdy w edycji dyplomatycznej zakodowane są wartości
rytmiczne przechodzące przez kreskę taktową, do linii filtra na dole
edycji należy dodać tie -s. W wyświetlaniu nuty i pauzy
zostaną rozbite na krótsze wartości rytmiczne, połączone ligaturami (w
przypadku pauz łuki nie wyświetlą się w edycji graficznej, ale ich
obecność pozwoli przywrócić dyplomatyczne kodowanie w razie gdy filtr
zostanie skompilowany).
W edycjach dyplomatycznych źródłowe niepoprawne akcydencje koduje się
za pomocą komentarza lokalnego !LO:N:acc=, który zmienia
poprawne kodowanie akcydencji na wariant źródłowy. Aby przywrócić
właściwe wyświetlanie w wariancie uwspółcześnionym edycji, należy
skorzystać z możliwości zmiany/usunięcia/dodania komentarza, opisanego
niżej (por. 4.3.1.2).
Jeśli w źródle (i transkrypcji dyplomatyczniej) oznaczenia
artykulacyjne są wpisane niepoprawnie, można je zmienić za pomocą
systemu SIC, analogicznie do zmiany opisanej wyżej (por. 4.2.8). Należy przy tym
pamiętać, że w parametrze s= znacznika SIC
umieścić należy wszystkie elementy, które nie powinny ulec zmianie.
W uwspółcześnionych edycjach źródłowe kierunki ogonków nut powinny
być ukryte. W tym celu do listy filtrów uwspółcześniających należy
dopisać autostem -r. Jeśli dla poprawnego wyświetlenia
uwspółcześnionej wersji edycji potrzebna jest ręczna zmiana kierunku
caudy, do dyplomatycznego kodowania należy dopisać dodatkowy znacznik
/ lub \. (chwilowo nie działa38).
Zastosowanie filtra autostem zlikwiduje też wyświetlanie
łamanych belek, co w przypadku zapisu jednogłosowego jest efektem
porządanym. Łamane belki należy zachować w przypadkach, gdy belka łączy
dźwięki na różnych pięcioliniach, lub jeśli brak łamania generuje
problemy z wyświetlaniem edycji.
Zapis łuków frazowych w edycjach uwspółcześnionych powinien być jak
najbliższy sytuacji źródłowej. Należy jednak poprawić łuki ewidentnie
błędne, a w przypadku prowadzenia partii równolegle, niespójną notację
należy ujednolicić. Najlepiej stosować w tym celu system
SIC. W parametrze s= zakodować należy zmiany
dotyczące miejsc rozpoczęcia i zakończenia łuku.
O tym, czy łuki frazowe i ligaturowe umieszczone są nad/pod nutami decyduje zgodność z zasadami współczesnej notacji muzycznej oraz wygląd partytury graficznej. W przypadku gdy większość łuków ma przypisaną niepoprawną pozycję (na przykład w związku ze zmianą klucza dawnego na współczesny), do linii filtrów uwspółcześniających należy dodać jeden z poniższych:
usuwanie kodowania pozycji łuków frazowych:
shed -k -e "s/([\(\)])[><]/\$1/g"
- usuwanie pozycji łuków ligaturowych:
shed -k -e "s/([\[\]])[><]/\$1/g"
- usuwanie pozycji obu łuków jednocześnie:
shed -k -e "s/([\(\)\[\]])[><]/\$1/g"
Belkowanie w edycjach uwspółcześnionych powinno być jak najbliższe zapisowi źródłowemu. Od tej zasady należy odstąpić, gdy głosy ewidentnie prowadzone równolegle mają inaczej rozłożone grupy nut. W takim przypadku belkowanie należy ujednolicić.
Wszelkie niestandardowe opcje zapisu grup niemiarowych w edycji
uwspółcześniającej powinny przybrać standardową formę. Może to oznaczać
potrzebę usunięcia znaczników typu
!LO:TUP:a/LO:TUP:b. Poniższy filtr zmieni
oznaczenie TUP na tup, dzięki czemu nie będzie
ono brane pod uwagę przy renederowaniu. Możliwe za to będzie
przywrócenie sytuacji dyplomatycznej po przypadkowym/celowym
skompilowaniu filtra uwspółcześniającego.
shed -k -e "s/:TUP:/:tup:/L"Zakodowane kustosze w edycji uwspółcześniającej należy ukryć,
stosując filtr shed -e "s/^custos:/Xcustos:/I". Filtr ten
zmieni *custos na *Xcustos we wszystkich
interpretacjach. Dzięki temu możliwe będzie przywtócenie kodowania
dyplomatycznego po skompilowaniu linii filtrów uwspółcześniających.
Powtórzenia całych taktów lub grup dźwięków zakodowane są w wersji
dyplomatycznej za pomocą oznaczeń *rep i
*Xrep. W wersji dyplomatycznej tego typu repetycje należy
rozwinąć, to znaczy przedstawić je za pomocą zapisu nutowego, a nie
symbolu. Aby to osiągnąć najlepiej jest zmienić wszystkie oznaczenia
*rep i *Xrep na *REP i
*XREP.
Można to osiągnąć, dodając następujący filtr do linii filtrów uwspółcześniających:
!!!filter: shed -e "s/^(X?)rep$/$1REP/I"Dzięki temu, nawet po przypadkowym lub celowym skompilowaniu filtra uwspółcześniającego, możliwe będzie odtworzenie sytuacji dyplomatycznej.
Ukryte fragmenty w edycji dyplomatycznej oznaczają, że w źródle oryginalnym fragment został zanotowany za pomocą znaku repetycji lub odsyłacza, albo też został pominięty. W edycjach uwspółcześnionych takie fragmenty powinny zostać wyświetlone.
W przypadku plików, w których wszystkie ukryte dźwięki powinny zostać
wyświetlone, najlepiej do linii filtra dodać
shed -e "s/yy//".
Jeśli w pliku część dźwięków lub pauz musi pozostać ukryta, można
oznaczyć je dodatkowym znaczniekiem yy - po zastosowaniu
powyższego filtra nie zostaną one wyświetlone.
Jeśli elementy do wyświetlenia w edycji uwspółcześnionej stanowią mniejszość elementów ukrytych, najwłaściwszym rozwiązaniem będzie zmiana pojedynczego tokenu (por. 4.3.1).
W wyjątkowych sytuacjach, gdy ukryty jest jeden głos kompozycji, a
zastosowanie filtra z innych względów jest niemożliwe, można zduplikować
spine **kern, zlikwidować znaczniki yy za
pomocą kombinacji filtrów kernview i shed, a
następnie zmienić jego nazwę na **kern-mod.
Należy przy tym pamiętać, że filtr uwspółcześniający nie może być wtedy aktywny!! Jego kompilacja może TRWALE USZKODZIĆ EDYCJĘ!!!!!
Oznaczenia dynamiczne w edycjach uwspółcześnionych powinny być zakodowane w formie zgodnej z zasadami współczesnej notacji muzycznej. Wszystkie niestandardowe oznaczenia skrótowe (np. pia. lub for) powinny zostać zmienione na odpowiednio p i f.
Wszystkie rodzaje oznaczeń dynamicznych powinny być za to ujednolicone w ramach grup instrumentów/głosów, jeśli nie ma ku temu przeciwwskazań muzycznych. Dla przykładu, jeśli dwoje skrzypiec gra wspólnie akompaniament, to oznaczenia dynamiczne powinny być takie same. Muszą się też zaczynać i kończyć w tych samych miejscach.
Oznaczenia dynamiczne mogą być uwspółcześniane na kilka różnych sposobów. Wybór właściwego zależy od kontekstu:
Zmiana tokenu (por. 4.3.1). Ten sposób sprawdzi się najlepiej przy zmianie lub usunięciu niepotrzebnego oznaczenia.
Dodanie brakującego oznaczenia w spinie **dynam,
oraz dodanie następujących linii komentarza lokalnego powyżej:
!LO:DY:t= :mod=%s
!LO:MO:mod=!LO:DY:ed=brack
!nullZastosowanie filtra modori -m pozwoli wyświetlić w
nawiasie kwadratowym.
skopiowanie spinu dynamiki, zmiana jego nazwy na
**dynam-mod i wprowadzenie odpowiednich poprawek (ten
wariant jest najbardziej użyteczny, gdy w wersji uwspółczesnionej trzeba
wprowadzić bardzo wiele zmian).
ukrycie linii !!!RDF**dynam: w stopce pliku, co
przywróci współczesne wyświetlanie oznaczeń. Można to zrobić za pomocą
funkcjonalności opisanej poniżej (por. 4.3.2).
Niezależnie od wybranego sposobu, oznaczenia dynamiczne, które nie
pojawiają się w źródle powinny być w wersji uwspółcześnionej ujęte w
nawias kwadratowy za pomocą komentarza lokalnego
!LO:DY:ed=brack.
Podobnie jak w przypadku oznaczeń dynamicznych (por. 4.2.19), teksty słowne kompozycji
można poprawiać albo za pomocą zmian pojdynczych tokenów (por. 4.3.1), albo przez zduplikowanie spinu
**text, zmianę jego nazwy na **text-mod i
wprowadzenia odpowiednich poprawek.
Pierwszy wariant rekomendowany jest dla poprawek pisowni pojedynczych sylab czy słów (np. -vs -> -us), drugi przyda się przy dalej idących zmianach podłożenia tekstu.
Tekst nieobecny w źródle, a dodany przez edytora powinien zostać ujęty w nawias kwadratowy.
Specjalnie na użytek tekstów staropolskich powstał filtr
humtr -p, który zmienia znaki specjalne, użyte w edycji
dyplomatycznej na znaki współczesne39.
Jeśli w jednym głosie źródła pojawia się niepotrzebny fragment, w edycji dyplomatycznej będzie on zakodowany (w pozostałych głosach pojawią się ukryte pauzy). W edycji uwspółcześnionej taki niepotrzebny fragment należy pominąć, stosując funkcjonalność ukrywania całych linii kodu Humdrum (por. 4.3.2).
W przypadku, gdy partia głosu/instrumentu jest wybrakowana, w szczególnych przypadkach można ją uzupełnić. Należy przy tym jednak zawsze pamiętać o tym, że ingerencja w treść muzyczną kompozycji powinna być możliwie najmniejsza.
Żeby dopisać pominięty fragment należy:
Skopiować fragment, który ma być zmieniony,
W skopiowanym fragmencie dopisać niezbędny fragment,
Przed pierwszą linią oryginalnego fragmentu dodać linię
!!LO:MO:ori, a po ostatniej -
!!LO:MO:end.
Przed pierwszą linią dodanego fragmentu dodać linię
!!LO:MO:mod, a po ostatniej linii =
!!LO:MO:end
Dodać !! przed każdą linią zapisu Humdrum dodanego
fragmentu.
Dodany fragment powinien być oznaczony kolorem szarym
(#aaa) (por. 4.1 i 4.2).
**kern **kern
*clefG2 *clefG2
*M3/4 *M3/4
=1 =1
2.c 4c
. 4d
. 4e
=2 =2
!!LO:MO:ori
2.d 2.ryy
!!LO:MO:end
!!LO:MO:mod
!! 2.d 4d@
!! . 4e@
!! . 4f@
!!LO:MO:end
=3 =3
2.e 4e
. 4f
. 4g
= =
*- *-
!!LO:MO:mod
!! !!!RDF**kern: @ = marked note, color=#aaa
!!LO:MO:end
modori -m
modori -mW zasadzie każdy token można zmienić w uwspółcześnionym widoku
stosując komentarz lokalny !LO:MO:mod=.
**kern
!LO:MO:mod=*2\left
*2\right
!LO:MO:mod=!LO:N:acc=n
!LO:N:acc=-
!LO:MO:mod=2een
2ddn
=
*-
!!!filter: modori -mPodobnie wygląda sytuacja z dodawaniem i usuwaniem tokenów, należy
przy tym pamiętać, że w takim przypadku potrzebny jest zawsze pusty
token (!null lub *null w przypadku komentarzy
i interpretacji, . w tokenach danych), który wstawiamy w
kodowaniu. Z kolei w linii modyfikującej należy dopisać parametr
:null. Istotne, by parametr ten znalazł się przed
parametrem mod=, inaczej zmiana nie zadziała poprawnie (np.
!LO:MO:null:mod=4c, a nie
!LO:MO:mod=4c:null)40.
Poniżej opisane zostały szczegóły takich operacji.
!LO:MO:mod=*modern
*original!LO:MO:null:mod=*null
*original!LO:MO:null:mod=*modern
*null**kern
=-
!LO:MO:mod=*modern
*original
1c
=
!LO:MO:null:mod=*null
*original
1c
=
!LO:MO:null:mod=*modern
*null
1c
=
*-
!!!filter: modori -mKomentarze lokalne zawierają przeważnie dwukropki, rozdzielające
parametry. Aby wstawić nowy komentarz lokalny, wszystkie dwukropki
należy zamienić na : (na przykład
!LO:TX:t=test ->
!LO:TX:t=test).
!LO:MO:mod=!LO:N:vis=2.
!LO:N:vis=4!LO:MO:null:mod=!null
!LO:N:vis=4!LO:MO:null:mod=!LO:N:vis=4
!null**kern
=-
!LO:MO:mod=!LO:N:vis=2.
!LO:N:vis=4
1c
=
!LO:MO:null:mod=!null
!LO:N:vis=4
1c
=
!LO:MO:null:mod=!LO:N:vis=4
!null
1c
=
*-
!!!filter: modori -mAby pominąć całe linie kodu Humdrum w wersji uwspółcześnionej należy
bezpośrednio przed pomijanym fragmentem dodać komentarz globalny
!!LO:MO:ori, a po ostatniej linii fragmentu
!!LO:MO:end. Należy przy tym uważać, by fragment, który
zostanie aktywny po pominięciu był poprawny od strony formalnej.
**kern
2c
2d
!!LO:MO:ori
=
2e
2f
!!LO:MO:end
=
1g
==
*-
!!!filter: modori -mmodori -m - filtr uwspółcześniający, pozwala na
wyświetlenie uwspółcześnionego kodowania utworu. Dokumentacja
sic - filtr nanoszący poprawki zakodowane w
komentarzu !LO:SIC. Dokumentacja
autostem -r - usuwa zakodowane kierunki
caud.
tie -s - rozdziela wartości rytmiczne, przechodzące
przez kreskę taktową.
humtr -p - zmienia niestandardowe znaki w edycjach
staropolskich na powrzechnie używane. Dokumentacja
shed - filtr umożliwiający zmienianie lub usuwanie
fragmentów kodowania. Dokumentacja
Dyftongi ,,æ” lub ,,œ” należy rozwinąć odpowiednio na ,,ae” lub
,,oe”. Abrewiacje tekstu rozwinąć zaś rozwinięcie umieścić w nawiasach
okrągłych – np. ,,ppter” zapisać jako ,,(pro)pter”, ,,ñ” jako
,,n(on)” a ,,Dñs” jako ,,D(ominu)s”.41
W wielu źródłach powtórki tekstu słownego oznaczane są skrótowo za
pomocą oznaczenia ≑ lub podobnego.42 Powtórzone słowa lub fragmenty
tekstu słownego w edycjach nutowych w formacie MusicXML należy umieścić
pomiędzy ukośnikami (/) – np. jeśli w źródle jest powtórka
,,Kyrie (” powinno być zapisane w transkrypcji jako ,,Kyrie
/Kyrie/”.
Poszczególne zwrotki tekstu słownego pod nutami powinny zostać zapisane jak w źródle. Możliwa jest sytuacja, gdy w źródle pod kolejnymi głosami podpisano różne zwrotki (z uwagi na oszczędność miejsca – zob. przyk. 6.1). Na prezentowanym przykładzie w źródle pod najwyższym głosem podpisano pierwszą zwrotkę, pod środkowym drugą, zaś pod najniższym pozostałe. W transkrypcji układ ten powinien pozostać zachowany. Nie należy dodawać numeracji zwrotek, o ile nie została wpisana w źródle.

W transkrypcji tekstu słownego należy stosować symbole i oznaczenia edytorskie. Zasadniczo w edycjach krytycznych posługujemy się nawiasami kwadratowymi, nawiasami okrągłymi i kursywą. W transkrypcjach dyplomatycznych użytwamy szerszego spektrum oznaczeń – poniżej lista oznaczeń wykorzystywanych w projekcie.
Nawiasy kwadratowe [ oraz ]: używamy do oznaczenia ubytków w tekście, wynikających z oczywistych pomyłek lub defektów źródła (urwanej bądź uszkodzonej karty itp.) a także rozwinięcia zapisów skrótowych (ale nie abrewiatur) – np. Trójca S[więta] (w źródle Trójca S.).
Nawiasy okrągłe ( oraz ): używamy do rozwinięcia abrewiatur tekstowych – np. O(mn)es (w źródle Oés).
Podwójne nawiasy kwadratowe [[ oraz ]]: używamy w celu oznaczenia
przekreślonych fragmentów tekstu – np. [[duszy]] (co odpowiada zapisowi
w źródle duszy).
Nawiasy trójkątne ⟨ oraz ⟩: używamy ich aby oznaczyć nieczytelny fragment tekstu, przy czym pomiędzy nimi wstawiamy taką ilość kropek, jaka odpowiada ilości znaków (liter) w źródle – np. ⟨.......⟩.
Kursywa (pismo pochyłe): za jej pomocą oznaczamy fragmenty
tekstu, które w źródle zostały powtórzone, a powtórkę oznaczono symbolem
graficznym – np. Alleluja alleluja alleluja (w źródle może
zostać zapisane Alleluja ≑ ≑). UWAGA: z uwagi na możliwości
konwertera, w plikach xml nie wprowadzamy kursywy w tekście tylko
oznaczamy początek i koniec wykursywowanego fragmentu za pomocą znaku /
(slash) – np. Alleluja /alleluja alleluja/. W plikach krn tekst taki
zostanie oznaczony poprzez *ij (otwierające) oraz
*Xij (zamykające) – zob. poniższy przykład.
**text
Al-
-le-
-lu-
-ja
*ij
al-
-le-
-lu-
-ja
*XijW transkrypcjach dyplomatycznych stosujemy tzw. transkrypcję typu A tekstu słownego. Zachowujemy oryginalną pisownię wielką i małą literą, nawet jeśli są to nazwy własne. Nazwy takie, jak bóg, syn człowieczy zapisujemy tak jak w źródle (z wielkiej lub małej litery). Jeśli w słowie występują więcej niż jedna wielka litera, zachowujemy pisownię. Nie zamieniamy małej litery na wielką nawet jeśli rozpoczyna ona zdanie (o ile w źródle jednoznacznie umieszczono literę małą).
Samogłoski zapisujemy zgodnie z ich pisownią w źródle – dotyczy to samogłosek jasnych i pochylonych. Zachowujemy także pominięcia akutu litery ó (zapisane jako ,,o”). Samogłoski nosowe zapisujemy zgodnie z źródłem (np. zięmia zapiszemy jako ,,zięmia”).
Pozostawiamy pisownię przedrostka s przed spółgłoskami w słowach np. smowa (pozostaje ,,smowa” a nie ,,zmowa”). Pozostawiamy oryginalną pisownię przez ,,K” lub ,,Ch” – np. Krzciciel, Krystus. Nie modernizujemy starych form, jak wszytcy, jestli (zostaje ,,jestli” a nie ”jeśli”). Zachowujemy także inne warianty pisowni, jak czistey (nie ,,czystej” lub ,,czystey”), poczieszenia (a nie ,,pocieszenia”), zesłąn (nie ,,zesłan”).
Nie modernizujemy formacji słowotwórczych, jak np. za prawdę (podpisane pod nutami w podziale na sylaby powinno być ,,za praw-dę” a nie ,,za-praw-dę”), lub zmartwych wstanie (w podziale na sylaby podpisane pod nutami ,,zmar-twych wsta-nie” a nie ,,zmar-twych-wsta-nie”).
Zachowujemy oboczności pisowni v oraz u zarówno w tekstach polskich jak i lacińskich (np. Vżalił zapisujemy jako ,,Vżalił” a nie ,,Użalił”; uenit jako ,,uenit” a nie ,,venit”).
Zachowujemy wszelkie akcenty zgodnie z oryginalnym kierunkiem – tzn. á, à, é, è, ó, ò. W spółgłoskach ć, ś, ń, ź kreskę zapisujemy zgodnie ze współczesną pisownią nawet, jeśli w źródle jest inaczej. Jeśli w źródle występuje długie s w postaci litery zachowujemy taką pisownię (np. iz zapisujemy jako ,,iz” a nie ,,isz” lub ,,iż”).
Interpunkcja powinna zostać wpisana jak w źródle, przy czym należy pamiętać, że zarówno w drukach jak i rękopisach dawniejszych wykorzystywano znak / lub \w funkcji przecinka. Taką sytuację ilustruje przyk. 6.2. Przykłady zapisów źródłowych wraz z właściwą ich transkrypcją i możliwymi błędami zestawiono w tabeli 6.1
| Zapis źródłowy | Transkrypcja | Zapis błędny |
|---|---|---|
| bòg | bòg | Bóg, bóg, Bòg |
| CHristus | CHristus | Christus, Chrystus, CHrystus |
| zięmia | zięmia | ziemia, Ziemia, Zięmia |
| sie | sie | się |
| się | się | sie |
| śrebro | śrebro | srebro |
| Krzciciel | Krzciciel | Chrzciciel, chrzciciel |
| zmartwych wstanie | zmartwych wstanie | zmartwychwstanie |
| czisteÿ | czisteÿ | czystey, czystej, czistey |
| łáski | łáski | łaski, łàski |
| nawÿsÿ | nawÿsÿ | nawyższy, najwyższy, nawÿssÿ, nawyssy |
Poniżej zaprezentowano kilka przykładów (przyk. 6.2, 6.3 oraz 6.4) zaczerpniętych ze źródeł, wraz z ich właściwą transkrypcją.

Dziećiątko dostoÿne, z blogoslawioneÿ dziewicze Marieÿ wneteś
raczel wstapić
w ziwot pannÿ czisteÿ dla odkupięnia i poczieszenia ludu
wszelkiego.
O(mn)es s(an)cti Angeli są dziś na niebie veseli nos eciam concinamus tu
na zÿemj.

Z_wielmozneÿ radÿ Troÿcze S.[więtej] zesłąn nawÿsÿ Archangioł do
Pannÿ Marieÿ,
Mieÿ panno wielkie pozdrowienie iuz sie przÿblizeło wzÿstkiemu swiatu
zbawie[nie]

Chlebie Angielski tobie częsć dawąmÿ, przÿstoÿne tobie triumphÿ
działąmÿ.
Tobie dziś daiem z_woÿskiem tÿch ludzi pokłon ÿ tesz pienie mÿ twoi
słudzÿ.
Przykład 6.3 wymaga dodatkowego komentarza. W pierwszym wersie na jednej nucie (pierwszej) występują dwie sylaby (,,z” ,,wiel-”). W takiej sytuacji sylaby należy połaczyć znakiem podkreślnika ,,_” bez spacji – czyli ,,z_wiel-”. Jednym z najczęstszych przypadków elizji będzie skrócenie formy ku tobie do ,,k tobie”. W takiej sytuacji należy zapisać formę w transkrypcji jako ,,k_tobie”.
W przykładzie 6.2 w ostatniej zwrotce rozwinięto abrewiatury tekstu łacińskiego: Oés zamieniono na O(mn)es. Nawiasy okrągłe oznaczają fragmenty tekstu, które zostały zapisane w źródle, ale w wersji skróconej w formie abrewiatury. Z kolei w przykładzie 6.3 w pierwszej linii uzupełniono fragment tekstu niezapisany, a uzupełnienie umieszczono w nawiasie kwadratowym: Troÿcze S. zapisano jako ,,Troÿcze S.[więtej]”. Było to konieczne, poneiważ bez uzupełnienia nie byłoby możliwe właściwe podpisanie tekstu słownego pod nutami.
W edycjach krytycznych zapis tekstu słownego powinien zostać uwspółcześniony zgodnie z zasadami tworzenia transkrypcji typu B. Poniżej umieszczono zestawienie dwu typów transkrypcji tekstu słownego: typu A i typu B (uwspółcześnionej). W transkrypcjach tego typu generalną zasadą jest uwspółcześnienie pisowni przy zachowaniu oryginalnej składni.
W tabeli 6.2 zebrano przykładowe zapisy źródłowe wraz z ich właściwą transkrypcją w edycjach krytycznych.
| Zapis źródłowy | Transkrypcja | Zapis błędny |
|---|---|---|
| bòg | Bóg | bòg, bóg, Bòg |
| CHristus | Chrystus | CHristus, Christus, CHrystus |
| zięmia | ziemia | zięmia, Zięmia |
| sie | się | sie |
| się | się | sie |
| śrebro | srebro | śrebro |
| Krzciciel | Chrzciciel | Krzciciel, chrzciciel |
| zmartwych wstanie | zmartwychwstanie | zmartwych wstanie |
| czisteÿ | czystej | czystey, czisteÿ, czistey |
| łáski | łaski | łáski, łàski |
| nawÿsÿ | najwyższy | nawÿsÿ, nawyższy, nawÿssÿ, nawyssy |
| vżalił | użalił | vżalił |
| xiąże | książę | xiąże |
| nÿebo ÿ ziemia | niebo i ziemia | niebo y ziemia |
| iáko jesus | jako Jezus | iako Jesus, jáko Jezus |
| Dziećiątko | Dzieciątko | Dziećiątko |
Dziećiątko dostoÿne, z blogoslawioneÿ dziewicze Marieÿ wneteś raczel wstapić
Dzieciątko dostojne, z błogosławionej dziewice Mariej wneteś raczył wstąpić
w ziwot pannÿ czisteÿ dla odkupięnia i poczieszenia ludu wszelkiego.
w żywot panny czystej dla odkupienia i pocieszenia ludu wszelkiego.
O(mn)es s(an)cti Angeli są dziś na niebie veseli nos eciam concinamus tu na zÿemj.
O(mn)es s(an)cti Angeli są dziś na niebie weseli nos eciam concinamus tu na ziemi.
Z_wielmozneÿ radÿ Troÿcze S.[więtej] zesłąn nawÿsÿ Archangioł do Pannÿ Marieÿ,
Z_wielmożnej rady Trójce świętej zesłan najwyższy Archanioł do Panny Mariej,
Mieÿ panno wielkie pozdrowienie iuz sie przÿblizeło wzÿstkiemu swiatu zbawie[nie]
Miej panno wielkie pozdrowienie już sie przybliżyło wszystkiemu światu zbawie[nie]
Chlebie Angielski tobie częsć dawąmÿ, przÿstoÿne tobie triumphÿ działąmÿ.
Chlebie Anielski tobie cześć dawamy, przystojne tobie triumfy działamy.
Tobie dziś daiem z_woÿskiem tÿch ludzi pokłon ÿ tesz pienie mÿ twoi słudzÿ.
Tobie dziś dajem z_wojskiem tych ludzi pokłon i też pienie my twoi słudzy.
W edycjach dyplomatycznych ekst słowny zawsze powinien zostać podzielony na sylaby i podłożony pod nutami zgodnie ze źródłem. Jeśli cały tekst odcinka/frazy wpisany jest tylko na początku, rozbity na sylaby tekst podpisać należy pod kolejnymi nutami tekstu muzycznego. Dwie sylaby mogą być przypisane do jedej nuty tylko w sytuacji, gdy sylab we frazie jest więcej niż nut.
W edycjach krytycznych tekst słowny powinien zostać podłożony pod nutami w zgodzie z obowiązującymi zasadami i praktyką wykonawczą epoki. W przypadku utworów XVIII i XIX wieku zwykle nie stanowi to problemu – tekst jest skrupulatnie podpisany pod nutami lub melodia nie pozostawia edytorowi miejsca na interpretację. W kompozycjach wcześniejszych zagadnienie to jest jednak znacznie bardziej skomplikowane. W źródłach szesnasto- i siedemnastowiecznych podłożenie tekstu słownego pod nutami jest przeważnie nieprecyzyjne – kopiści i drukarze ze względu na oszczędność papieru i czasu stosowali skróty myślowe i uproszczenia, pozostawiając kwestie rzeczywistego podłożenia wykonawcom. Te same źródła wskazują, że wykonawcy dzięki doświadczniu i znajomości zasad podkładania tekstu radzili sobie z tym problemem automatycznie, zazwyczaj nawet bez potrzeby wprowadzania notatek. Zasady, o których mowa opisywało czterech teoretyków szesnastowiecznych: Giovanni Maria Lanfranco (Scintille di musica [1533]), Nicola Vicentino (L’Antica musica ridotta alla moderna prattica [1555]), Gioseffo Zarlino (Istitutioni harmoniche [1558]) oraz Gaspar Stocker (Stoquerus) (De musica verbali libri duo [1570])43. Badania wskazują, że Zarlino w swoim dziele powtarza tezy Lanfranca uzupełniając je nieco. Z kolei traktat Stoquerusa do de facto wyjaśnienie traktatu Zarlina. Zasady Vicentina różnią się nieco od pozostałych, które z powodów opisanych powyżej są spójne – Vicentino jako jedyny zajął się muzyką świecką w językach innych niż łacina.
Szesnastowieczne zasady podkładania tekstu można sprowadzić do poniższych reguł, wspólnych dla większości wyżej wymienionych traktatów:
Każda nuta dłuższa od semiminimy może być nośnikiem sylaby. Semiminima również – w wyjątkowych okolicznościach – może być powiązana z sylabą tekstu słownego, przy czym należy wtedy pamiętać o stosowaniu kolejnych zasad:
Jeśli sylaba jest przypisana do semiminimy, kolejna sylaba powinna być przypisana do następującej po niej nucie.
Jeśli to możliwe, tylko pierwsza z ciągu semiminim może być nośnikiem sylaby.
Nuta następująca po ciągu semiminim nie powinna być powiązana z sylabą.
Prawidłowe podłożenie tekstu pod semiminimami prezentuje przykład 6.5.

Każda ligatura, niezależnie od tego z ilu dźwięków się składa może być powiązana z tylko jedną sylabą (por. przykład 6.6).
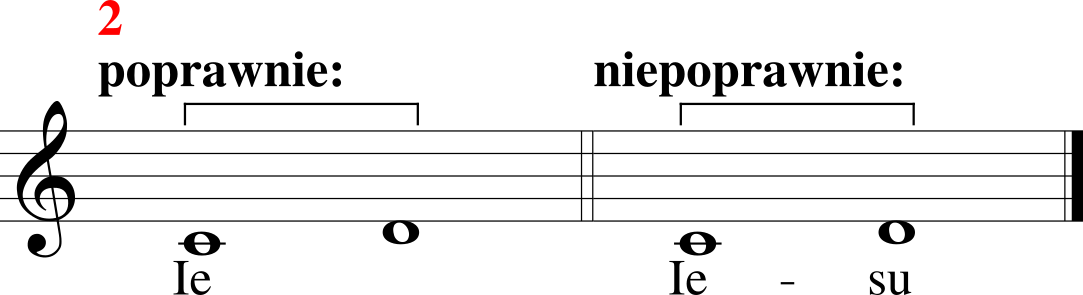
Kropka przedłużająca wartość rytmiczną nuty nie jest nośnikiem sylaby.
Nuta występująca po kropce przedłużającej poprzednią nutę mogą być nośnikiem sylaby tylko jeśli jej wartość jest równa lub większa od wartości kropki, co ilustruje przykład 6.7.

Pierwszy dźwięk melodii, lub dźwięk bezpośrednio po pauzie powinien być nośnikiem sylaby.
Powtórzenia tekstu są możliwe, należy przy tym pamiętać, by powtarzany fragment był spójny semantycznie – powtarzania pojedynczych wyrazów należy w związku z tym unikać.
Melizmaty – o ile to możliwe – powinny być przypisane do ostatniej akcentowanej sylaby.
Jeśli nie stoi to w sprzeczności z innym zasadami, ostatnia nuta frazy powinna być powiązana z sylabą.
Nicola Vicentino stworzył własny zestaw dwunastu reguł podkładania tekstu pod nutami. Pięć z nich pokrywa się z wyżej wymienionymi, pięć to raczej wskazówki wykonawczo-kompozytorskie. W związku z powyższym należy w tym miejcu przytoczyć tylko dwie zasady:
Przy skoku oktawowym nowa sylaba powinna się pojawić na drugim dźwięku.
Zmiana sylaby nie powinna pojawiać się na dysonansie – zostaje on wtedy niepotrzebnie uwypuklony.
Warto w tym miejscu podkreślić, że wszystkie cztery wymienione traktaty powstały jako reakcja teoretyków na złe praktyki wykonawcze i kompozytorskie. Oznacza to, że w literaturze muzycznej szesnastego i sedemnastego wieku odnaleźć można znaczną liczbę odstępstw od powyższych reguł. W praktyce oznacza to, że przytoczone zasady mogą okazać się nieprzydatne czy też niemożliwe do wdrożenia.
Niniejszy rozdział instrukcji dotyczy kodowania muzyki zapisanej w formie nowoniemieckiej tabulatury organowej. Źródła zapisane tą notacją powstawały w Polsce od drugiej połowy XVI wieku i stanowią istotne źródło repertuaru i wiedzy o dawnej kulturze muzycznej na terenach Rzeczypospolitej. Najważniejszym, a zarazem najobszerniejszym tego typu zabytkiem w Polsce jest tzw. tabulatura pelplińska — sześciotomowy rękopis, spisany w większości w pierwszej połowie XVII wieku, zawierający (według katalogu opublikowanego w 1963 roku w ramach serii Antiquitates Musicae in Polonia) ponad 900 utworów z przełomu XVI i XVII wieku.
Do potrzeb kodowania tego typu zapisu proponujemy nowy format cyfrowego zapisu muzycznego — GOT (od german organ tabulature) — stworzony w 2025 roku przez Marcina Konika, a uzupełniony przez Craiga Sappa i Jacka Iwaszkę. Z założenia format ten wizualnie ma przypominać zapis tabulaturowy: warstwa rytmiczna wpisywana jest nad warstwą melodyczną każdego głosu, materiał muzyczny uporządkowany jest w bloki, odpowiadające taktom, tekst słowny notuje się pod najniższym głosem. Technicznie GOT ten oparty jest na formacie TSV (tab separated values), w praktyce zaprojektowano go tak, żeby można było go wpisywać w edytorach arkuszy kalkulacyjnych takich jak Excel, LibreOffice Calc czy Google Sheets. W projektach NIFC wykorzystywane będzie ostatnie z wymienionych narzędzi, bo jako jedyne umożliwia jednoczesny dostęp do plików dla wielu użytkowników, pozwala też na wprowadzenie dedykowanych narzędzi walidacyjnych i edytorskich. Transkrypcje w formacie GOT mogą być automatycznie przekonwertowane do formatu Humdrum, co umożliwia redaktorom sprawdzenie zapisu już w formie współczesnej notacji nutowej w oprogramowaniu Verovio Humdrum Viewer.
Prace nad redakcją utworu zapisanego za pomocą nowoniemieckiej
tabulatury organowej w projektach NIFC rozpocząć należy od stworzenia
zakładki w odpowiednim arkuszu Google Sheets (linki do arkuszy zostaną
udostępnione redaktorom indywidualnie). W przypadku tabulatury
pelplińskiej zakładce należy nadać nową nazwę w formacie
pelplin-[numer katalogowy w formacie trzycyfrowym], na
przykład pelplin-008, pelplin-111.
Warto też zmienić format zapisu numerów, żeby uniknąć negatywnych
efektów działania autokorekty, wbudowanej w Arkusze Google. W tym celu
należy podświetlić wszystkie komórki ([Ctrl] + [A][A]), a
następnie ustawić styl wyświetlania numerów na tekstowy
(Format Number Plain
text).
Na podstawie nazwy zakładki skrypt wbudowany w arkusz może zaciągnąć metadane utworu. W tym celu należy kliknąć ikonkę GOT Tools, a następnie wybrać Update Metadata. Dane importowane są z osobnego arkusza metadanych i w razie zmian mogą być automatycznie aktualizowane w plikach transkrypcji. Dane te mają formę zbliżoną do tych, wykorzystywanych w formacie Humdrum:
!!!ONM 144
!!!volume 1
!!!incipit Jubilate Deo
!!!lang Latin
!!!COM Pacelli, AsprilioRedaktor powinien w sekcji metadanych dodać następujące pola:
!!!page — numery stron według paginacji
źródłowej
!!!ENC — imię i nazwisko edytora
pliku
!!!END — data ukończenia
edycji
Celem stworzenia formatu kodowania GOT było przyspieszenie i ułatwienie procesu tworzenia dyplomatycznych edycji muzycznych źródeł zapisanych niemiecką notacją tabulaturową. Kolejność wprowadzania danych odpowiada kolejności, w jakiej odczytuje się źródło, a układ pliku GOT także wizualnie przypomina zapis tabulaturowy (por. 7.1 i 7.2). W tabulaturach wyraźnie rozdzielono poszczególne głosy kompozycji — w tabulaturach pelplińskich zanotowano utwory od 2 do 9 głosów. Każdy głos zapisano w osobnej linii. Notacja muzyczna zajmuje zwykle obie strony rozkładówki, przechodzi płynnie ze strony verso (lewej) na recto (prawą) i dopiero wtedy następuje łamanie linii. Tekst słowny zanotowany jest pod najniższym głosem. Treść muzyczna uporządkowana jest w rubryki, które odpowiadają współczesnym taktom. Takty w metrum dwudzielnym najczęściej zawierają dwie grupy rytmiczne, każda o długości całej nuty (semibrevis), w metrum trójdzielnym częściej jest to cała nuta (semibrevis) z kropką. Kropka przedłużająca wartość dźwięku, przechodząca między grupami w ramach taktu lub między taktami notowana jest nie na końcu grupy przy wartości rytmicznej, a raczej na początku grupy następnej, co dopełnia jej długość do całej nuty.

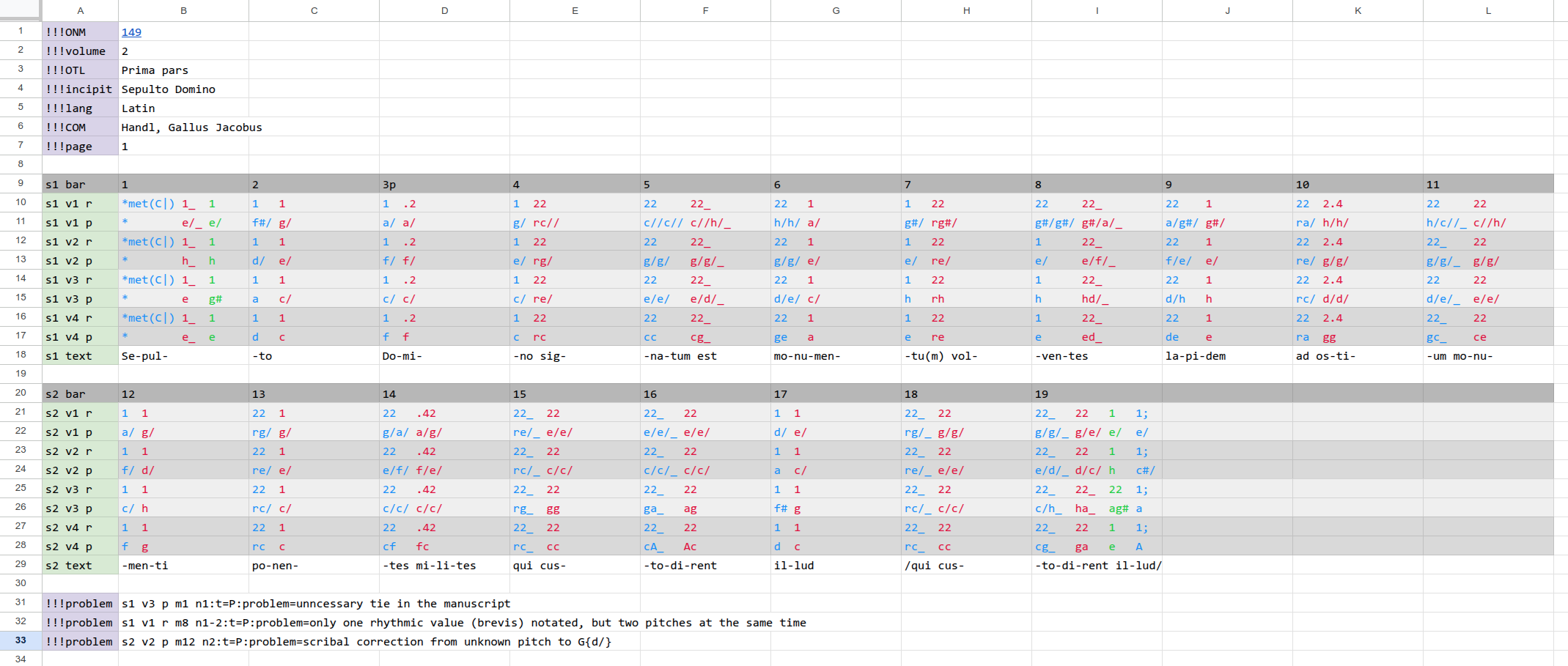
Struktura pliku GOT nawiązuje do opisanej wyżej struktury zapisu
źródłowego. Kolejne wiersze arkusza kalkulacyjnego odpowiadają
poszczególnym głosom, kolumny z kolei oddają takty. Końcowi linii w
źródle odpowiada też koniec linii w formacie GOT. W pierwszej kolumnie
formatu GOT zawsze znajdują się etykiety, określające jakie dane będą
wpisywane dalej. Mogą to być pola metadanych, rozpoczynające się od
!!!, albo pola danych, każdorazowo kodowane w tej samej
kolejności — numeracja taktów, zapis rytmu, wysokości dźwięków lub tekst
liryczny:
Numeracja taktów: Etykieta linii numeracji
taktów kodowana jest według wzoru s[numer systemu] bar, na
przykład s1 bar, lub s3 bar. W kolejnych
kolumnach koduje się kolejne numery taktów. W takcie, w którym w
rękopisie wypada zmiana strony z verso na recto po
numerze taktu dodajemy p, na przykład
3p.
Linie rytmu: etykieta linii rytmu składa
się z oznaczenia numeru systemu (s[numer systemu]), numeru
głosu (v[numer głosu]) oraz litery r, na
przykład s1 v1 r lub s2 v4 r.
Linie wysokości dźwięków: etykieta
zbudowana jest analogicznie do linii rytmu, jedyna różnica to litera na
końcu - wysokości dźwięków oznaczamy literą p, na przykład
s1 v1 p lub s4 v3 p.
Tekst liryczny: linię w której zakodowany
będzie tekst liryczny oznacza się według schematu
s[numer systemu] text, na przykład
s2 text.
Rytm kodowany jest za pomocą cyfr, według schematu przedstawionego poniżej (por. 7.3). Podział na takty i grupy w ramach taktu powinien być zgodny ze źródłem. Grupy wewnątrz taktu powinny być rozdzielone przynajmniej jedną spacją.
W każdym takcie kodujemy tyle grup ile zostało zapisane w rękopisie, nawet jeśli nie jest to zgodne z współczesnymi normami.
W rzadkich przypadkach źródłowy zapis rytmiczny wymaga zastosowania
wartości rytmicznej 0 (brevis) i braku podziału na
grupy rytmiczne. Dzieje się tak w przypadku pauz całotaktowych,
zapisanych odpowiednim symbolem, lub ostatnich dźwięków. W pozostałych
przypadkach, na przykład w przypadku pominiętych pauz całotaktowych
należy stosować podział na grupy, zgodne z pozostałymi głosami.
Kropka przedłużająca wartość rytmiczną może być:
zakodowana przy oznaczeniu rytmicznym — jeśli nie wykracza
poza grupę rytmiczną lub poza takt (np.
4.82 24.8)
zakodowana na początku grupy rytmicznej — dzieje się tak,
gdy przedłużany jest ostatni dźwięk poprzedniej grupy (na przykład
22 .42).
Niektórzy kopiści rękopisów pelplińskich stosowali zapis skrótowy dla
grup takich samych wartości rytmicznych — zamiast notować cztery
oznaczenia rytmiczne, stawiali jeden znak nad czterema dźwiękami. Tego
typu sytuacje również kodujemy w sposób skrótowy — podając cyfrowe
oznaczenie wartości rytmicznej (np. 4 dla
semiminimy) a następnie x i określenie, ile razy
wartość jest powtórzona, na przykład 4x4 lub
4x3.
Pauzy krótsze od semibrevis kopiści zapisują najczęściej zapisują przez przeniesienie oznaczenia rytmicznego do linii wysokości dźwięków. W formacie GOT kodowanie rytmu trzeba jednak przenieść do linii rytmicznej.
Łuk ligaturowy kodowany jest bezpośrednio przy oznaczeniu rytmicznym
w formie podkreślenia (_), na przykład
22_ 22.
Fermatę na końcu utworu dodaje się po oznaczeniu rytmicznym za pomocą
średnika (;), np. 1 1;.
W linii rytmicznej koduje się również oznaczenia menzuralne. Ich
forma zbliżona jest do kodowania w formacie Humdrum (por. 3.16), np. *met(C|) lub
*met(3). Koduje się je jako osobną grupę, oddzieloną od
zapisu rytmu przynajmniej jedną spacją. Oznaczenie metryczne umieszczamy
na początku taktu, nawet jeśli w źródle zakodowano je pod koniec taktu
poprzedniego, lub w osobnym takcie na początku utworu.
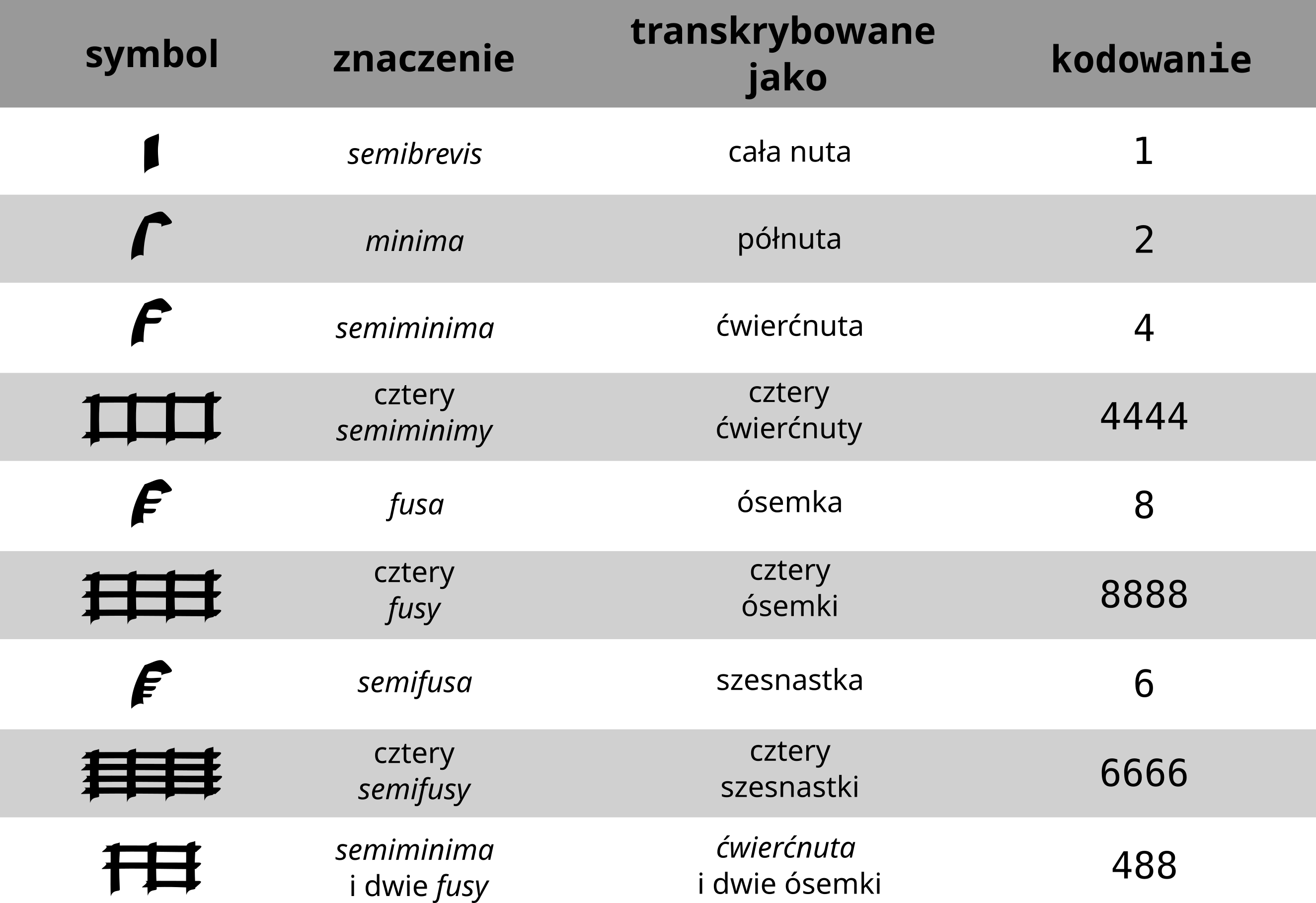
Z tabeli przytoczonej jako 7.3 wynika,
że wartości rytmiczne mniejsze od minimy (półnuty) mogą
podlegać grupowaniu w rękopisie. Domyślnie należy spodziewać się grup o
łącznej wartości semibrevis (całej nuty). Czasem jednak zdarza
się, że te grupy takie są rozdzielone na mniejsze - w takich przypadkach
należy stosować nawiasy (( i )), aby zaznaczyć
miejsca przerwania grupy. Nie jest konieczne zamykanie nawiasami
wszystkich grup - zamiast zapisu (88)(4488) możemy
zastosować (88)4488 lub 88(4488). Gdyby
powyższy rytm zapisany był w trzech grupach ((88)(44)(88)),
w nawias wystarczyłoby wziąć środkową grupę (88(44)88).
Pauzy nie podlegają grupowaniu, więc grupy przerwane przez nie nie muszą
być dodatkowo oznaczone nawiasami. Taki zapis w formacie GOT nie jest
konwertowany do formatu Humdrum, nie ma w związku z tym wpływu na nutową
edycję kompozycji.
Wysokości dźwięków w nowoniemieckiej tabulaturze organowej zapisane są za pomocą nazw literowych (c, d, e, f, g, a, b, h). O ile do rozróżnienia b i h stosuje się osobne znaki, o tyle pozostałe akcydencje notuje się za pomocą wydłużonej lub ozdobionej linii wykańczającej znak (por. 7.4). Warto zwrócić uwagę, że w zapisie tabulaturowym nie ma odpowiednika bemola — dźwięk es zapisuje się zawsze jako dis.

W zapisie tabulaturowym stosuje się wielkie i małe litery: dźwięki w oktawie wielkiej zapisuje się wielkimi literami, a dźwięki w oktawie małej — małymi. Kolejne, wyższe oktawy oznacza się za pomocą poziomych kresek nad małymi literami. I tak dźwięki z jedną poziomą kreską należą do oktawy razkreślnej, a z dwiema kreskami — dwukreślnej.
Kodowanie w formacie GOT odwzorowuje zapis oryginalny — wielkie
litery w tabulaturze należy kodować wielkimi literami, a litery małe
małymi. Kreski nad nutami w kodowaniu oddawać należy za pomocą ukośników
(/) — c z jedną kreską zakodujemy jako
c/, a c z dwiema kreskami jako c//.
Akcydencje zapisujemy za pomocą znaku # — cis
zakodujemy więc jako c#. dis, zastosowane w
znaczeniu es należy zapisać w formacie GOT jako
d#.
Pauzy kodujemy za pomocą litery r. Jeśli w źródle
zamiast pauzy zastosowano puste miejsce, kodujemy pauzę ukrytą
(ry).
Łuki ligaturowe powinny być zakodowane w obu warstwach — rytmicznej i melodycznej. Z kolei kropki przedłużające wartość rytmiczną należy przenieść do warstwy rytmicznej, nawet jeśli w źródle zapisano je w linii wysokości dźwięków.
Tekst liryczny kompozycji w tabulaturach zapisany jest pod notacją muzyczną. Tak też powinien zostać zakodowany w formacie GOT. Kodowanie powinno jak najlepiej oddawać zapis źródłowy - słowa powinny być umieszczone w komórkach tabeli zgodnie ze źródłowym podziałem na takty.
Słowa powinny być podzielone na sylaby za pomocą dywizów, (np.
Ne for-te ve-ni-ant). Jeśli słowo zaczyna się w jednym
takcie, a kończy w następnym, dywiz umieszczamy zarówno na końcu
ostatniej, jak i na początku pierwszej sylaby w komórkach, np.
di-cant ple- | -bi sur- | -re-xit a mor- | -tu-is.
Powtórzenia zanotowane za pomocą znaku repetycji należy kodować między
ukośnikami (np. /Al-le-lu-ia/). Abrewiacje należy rozwinąć,
umieszczając pominięte litery w nawiasie, na przykład
D(o-mi)-ni. Poza tym należy stosować pisownię źródłową,
nawet jeśli jest niekonsekwentna, niezgodna z ortografią czy wariantowa
w stosunku do ogólnie przyjętej.
Tabulatury sporadycznie zawierają notatki, wprowadzone przez kopistów, które powinny zostać ujęte w edycjach. W zapisie źródłowym mogą też pojawić się błędy, wymagające specjalnego kodowania. W obu przypadkach informacje powinny zostać zakodowane na końcu pliku i oznaczone właściwą etykietą. Oprócz etykiety, ustandaryzowany jest także sposób kodowania odpowiedniego miejsca w transkrypcji, rozpoczynający każdą z notatek — zawiera on:
numer systemu (s[numer])
numer głosu (v[numer])
oznaczenie, czy notatka dotyczy zapisu rytmicznego czy
melodycznego (r/p)
numer taktu (m[numer])
numer nuty w takcie (n[numer])
Dla przykładu, oznaczenie s5 v3 r m60 n1 oznacza, że
notatka dotyczy pierwszego oznaczenia rytmicznego w t. 60, w głosie
trzecim, który zakodowano w systemie piątym.
Jeśli w notatce podana jest wysokość, lub oznaczenie rytmiczne w
formacie GOT, należy je zakodować w formie
G{[wartość rytmiczna/wysokość]}, np. G{2} lub
G{d#//}.
Właściwą etykietą dla kodowania adnotacji skryptorskich jest
!!!LO:TX. W polu danych umieszczamy oznaczenie miejsca, a
następnie, po dwukropku wpisujemy t=[odpis notatki].
Poniższe kodowanie umożliwia zapisanie następującej notatki (por. 7.5):
!!!LO:TX s4 v8 p m55 n1:t=Cito verte \n et perge.
W przypadku ewidentnych pomyłek skryptorskich, które mogą zdarzyć się
zarówno w warstwie dźwiękowej jak i rytmicznej, w transkrypcji należy
zakodować poprawioną wartość. Zapis źródłowy oddaje się
w notatce typu SIC, którą oznacza się etykietą
!!!SIC. W polu danych podać należy odnośnik do miejsca w
edycji, a po dwukropku dodać o=[właściwa wartość], na
przykład:
!!!SIC s3 v1 r m41 n2:o=G{1}
!!!SIC s5 v3 p m58 n1:o=G{d}W przypadkach, gdy sytuacja źródłowa jest niejednoznaczna, lub
zdaniem edytora wymaga doprecyzowania, należy stosować notatkę typu
problem, opatrzoną etykietą !!!problem. Pole
danych powinno zawierać odnośnik miejscowy, a następnie po dwukropku
t=P:problem=[opis problemu w języku angielskim], na
przykład:
!!!problem s1 v3 r m11 n1-5:t=P:problem=illegible rhythm due to the paper defects
!!!problem s5 v4 p m61 n2:t=P:problem=unnecessary tie
Kod GOT:
s1 bar 1 2 3 4 5
s1 v1 r *met(C|) 22 1 22 .42 22 .42 1 1 22 22_
s1 v1 p * ra/ g#/ g#/g#/ g#/g#/ a/c// c//h/ a/ g#/ rg/ a/h/_
s1 v2 r *met(C|) 22 1 22 22 22 .42 1 1 22 22_
s1 v2 p * re/ e/ e/e/ e/e/ f#/g/ g/g/ e/ e/ re/ f#/g/_
s1 v3 r *met(C|) 22 1 22 .42 22 .42 1 1 22 22_
s1 v3 p * rc/ h hh hh d/e/ e/d/ c/ h rh d/d/_
s1 v4 r *met(C|) 1 1 22 .42 22 .42 1 1 22 22_
s1 v4 p * a e ee ee dc cg a e re dg_
s1 text Ne for-te ve-ni-ant dis-ci-pu-li e-ius et fu-r(en)-
Arkusze Google, w których kodowane są utwory z tabulatur pelplińskich zostały wyposażone w skrypty i narzędzia ułatwiające prace transkrypcyjne. Narzędzia te dostępne są w dodanym menu (por. 7.9).
Validate Score — sprawdza poprawność składniową danych i włącza warunkowe formatowanie komórek, ułatwiające wzrokową orientację w kodowaniu;
Align Voice Rhythm/Pitch — dopasowuje odstępy między kodowaniem rytmu i melodii w ramach jednego głosu;
Align System Rhythm/Pitch — dopasowuje odstępy między kodowaniem rytmu i melodii w ramach całego systemu;
Update Metadata — zaciąga najbardziej aktualne metadane pliku;
Open in Verovio Humdrum Viewer — generuje link pozwalający na otwarcie oprogramowania VHV i wyświetlenia za jego pomocą zapisu nutowego na podstawie danych przekonwertowanych do formatu Humdrum.
Doświadczenie uczy, że przy odczytywaniu i kodowaniu zapisu tabulaturowego nietrudno popełnić błędy. Poniżej wymieniono kilka najczęściej występujących problemów.
Pismo niektórych kopistów i sposób pisania liter w XVII wieku sprawia, że litera d często przypomina współczesne g (por. 7.10). Warto w związku z tym zwrócić uwagę na sposób zapisu tych liter przed rozpoczęciem prac, a następnie pilnować, czy odczytanie było prawdziwe.

Najczęstszym błędem zaobserwowanym przy pracach transkrybenckich jest
pominięcie oznaczenia oktawy (/), zazwyczaj na końcu grupy
rytmicznej. Najłatwiej wykryć tego błędy, wyszukując duże skoki melodii
po konwersji do formatu Humdrum.
W tabulaturach pelplińskich często trudno rozpoznać wielkość litery
c w partiach najniższego głosu. Warto jednak przyjąć, że w
kompozycjach z przełomu XVI i XVII wieku nie występuje dźwięk C
w oktawie wielkiej. Wzwiązku z tym wszystkie wątpliwe przypadki należy
rozwiązywać na korzyść c w oktawie małej i kodować je jako
c, chyba że przesłanki muzyczne będą wskazywać inaczej.
| grupa | instrument |
|---|---|
| Dęte drewniane | Flety |
| Oboje | |
| Klarnety | |
| Fagoty | |
| Dęte blaszane | Rogi |
| Clarini | |
| Puzony | |
| Kotły | |
| Głosy | Soprano |
| Alto | |
| Tenore | |
| Basso | |
| Instrumenty smyczkowe | Skrzypce I |
| Skrzypce II | |
| Altówka | |
| Wiolonczela | |
| Basso | |
| Organy |
strokes.py to skrypt, który pozwala zmienić kreseczki
artykulacyjne zakodowane jako komentarz tekstowy
(!LO:TX:t=|) na właściwe kodowanie (| +
!!!RDF**kern: | = vertical stroke).
Skrypt został napisany w języku Python (v. 3.6), nie wymaga instalowania dodatkowych pakietów.
Sposób użycia: skrypt należy skopiować do pliku tekstowego
strokes.py, a następnie zmienić uprawnienia na wykonywalne.
Aby użyć skryptu należy wpisać:
./strokes.py [input-file].krn > [output-file].krn#!/usr/bin/python3
import sys
import csv
import re
######################################
def checktoken ( str ):
if re.search(r'^!', str):
type = "l"
elif re.search(r'^\*', str):
type = "i"
elif re.search(r'^\.', str):
type = "n"
elif re.search(r'^\=', str):
type = "m"
else:
type = "d"
return type
#######################################
def nonLocalEmpty ( list ):
for t in list:
emptycheck = 0
if re.search(r'^!$', t):
pass
else:
emptycheck += 1
if emptycheck > 0:
return True
#######################################
argv = (sys.argv)
#filecontent =
data = list(csv.reader(open(argv[1]), delimiter="\t"))
spinecount = 0
l=0
while (l < len(data)):
if len(data[l]) > spinecount:
spinecount = len(data[l])
l += 1
print(f"spinecount = {spinecount}", file=sys.stderr)
line=0
spine=0
changes=0
position = None
while (len(data[line]) <= spinecount):
strokeON = "OFF"
while (line < len(data)):
if len(data[line]) <= spine:
line += 1
continue
else:
checkMatch = re.search(r'!LO:TX:[iB]?:?([ab])?:?[iB]?:?t=\|:?p?r?o?b?l?e?m?$', data[line][spine])
if checkMatch:
position = checkMatch.group(1) if checkMatch else None
strokeON = "ON";
data[line][spine] = "!"
changes += 1
line += 1
continue
if strokeON == "ON":
if checktoken(data[line][spine]) == "d":
data[line][spine] += "|"
print(f"position found:{position}", file=sys.stderr)
if position == "a":
data[line][spine] += ">"
elif position == "b":
data[line][spine] += "<"
else:
pass
strokeON = "OFF"
line += 1
line = 0
spine += 1
if spine >= spinecount:
break
rdfStroke=0
catline = []
rdfIndex = 0
i=0
while (i < len(data)):
if re.search(r"^\!\!\!RDF\*\*", data[i][0]):
if re.search(r"\| = vertical stroke", data[i][0]):
rdfStroke += 1
else:
rdfIndex = i
if nonLocalEmpty(data[i]):
catline.append("\t".join(map(str,data[i])))
i += 1
if changes > 0:
if rdfStroke == 0:
if rdfIndex > 0:
catline.insert(rdfIndex,"!!!RDF**kern: | = vertical stroke")
else:
catline.append("!!!RDF**kern: | = vertical stroke")
print(argv[1], file=sys.stderr)
print("\n".join(map(str,catline)))
{kind=link}